9,883+% Returns in 3 years on Cryptocurrency using 2D Convolutional Neural Network (CNN) Model and short listing Best Assets for Trading — VishvaAlgo Machine Learning Trading Bot
Unleashing the power of Neural Networks for creating Trading Bot for maximum profits.
Introduction:
Welcome to the world of algorithmic trading and machine learning, where innovation meets profitability. Over the past three years, I’ve dedicated myself to developing algorithmic trading systems that harness the power of various strategies. Through relentless experimentation and refinement, I’ve achieved impressive returns across multiple strategies, delighting members of my Patreon community with consistent profits.
In the pursuit of excellence, I recently launched VishvaAlgo, a machine learning-based algorithmic trading system that leverages neural network classification models. This cutting-edge platform has already demonstrated remarkable results, delivering exceptional returns to traders in the cryptocurrency market. Through a series of articles and practical demonstrations, I’ve shared insights on transitioning from traditional algorithmic trading to deploying practical machine learning models, showcasing their effectiveness in real-world trading environments.
In this article, we delve into the trans-formative potential of algorithmic trading and machine learning, focusing on the effectiveness of neural networks, specifically the Convolutional neural networks (CNNs) models. Building upon our past successes, we set out to demonstrate the remarkable profitability achievable with advanced machine learning models, using Bitcoin (BTC) and Ethereum (ETH) as our primary assets.
Our analysis focuses on Ethereum pricing in USDT, utilizing 15-minute candlestick data spanning from January 1st, 2021, to October 22nd, 2023, comprising over 97,000 rows of data and more than 190 features. By leveraging neural network models for prediction, we aim to identify optimal long and short positions, showcasing the potential of deep learning in financial markets.
Our story is one of relentless innovation, fueled by a burning desire to unlock the full potential of Deep Learning in the pursuit of profit. In this article, we invite you to join us as we unravel the exciting tale of our transformation from humble beginnings to groundbreaking success.

Our Algorithmic Trading Vs/+ Machine Learning Vs/+ Deep Learning Journey so far?
Stage 1:
We have developed a crypto Algorithmic Strategy which gave us huge profits when ran on multiple crypto assets (138+) with a profit range of 8787%+ in span of 3 years (almost).
“The 8787%+ ROI Algo Strategy Unveiled for Crypto Futures! Revolutionized With Famous RSI, MACD, Bollinger Bands, ADX, EMA” — Link
We have run live trading in dry-run mode for the same for 7 days and details about the same have been shared in another article.
“Freqtrade Revealed: 7-Day Journey in Algorithmic Trading for Crypto Futures Market” — Link
After successful backtest results and forward testing (live trading in dry-run mode), we planned to improve the odds of making more profit for the same. (To lower stop-losses, increase odds of winning more , reduce risk factor and other important things)
Stage 2:
We have worked on developing a strategy alone without freqtrade setup (avoiding trailing stop loss, multiple asst parallel running, higher risk management setups that freqtrade provides for free (it is a free open source platform) and then tested it in market, then optimized it using hyper parameters and then , we got some +ve profits from the strategy
“How I achieved 3000+% Profit in Backtesting for Various Algorithmic Trading Bots and how you can do the same for your Trading Strategies — Using Python Code” — Link
Stage 3:
As we have tested our strategy only on 1 Asset , i.e; BTC/USDT in crypto market, we wanted to know if we can segregate the whole collective assets we have (Which we have used for developing Freqtrade Strategy earlier) segregate them into different clusters based on their volatility, it becomes easy to do trading for certain volatile assets and won’t hit huge stop-losses for others if worked on implementing based on coin volatility.
We used K-nearest Neighbors (KNN Means) to identify different clusters of assets out of 138 crypto assets we use in our freqtrade strategy, which gave us 8000+% profits during backtest.
“Hyper Optimized Algorithmic Strategy Vs/+ Machine Learning Models Part -1 (K-Nearest Neighbors)” — Link
Stage 4:
Now, we want to introduce Unsupervised Machine Learning model — Hidden Markov Model (HMMs) to identify trends in the market and trade during only profitable trends and avoid sudden pumps, dumps in market, avoid negative trends in market. Below explanation unravels the same.
“Hyper Optimized Algorithmic Strategy Vs/+ Machine Learning Models Part -2 (Hidden Markov Model — HMM)” — Link
Stage 5:
I worked on using XGBoost Classifier to identify long and short trades using our old signal. Before using it, we ensured that the signal algorithm we had previously developed was hyper-optimized. Additionally, we introduced different stop-loss and take-profit parameters for this setup, causing the target values to change accordingly. We also adjusted the parameters used for obtaining profitable trades based on the stop-loss and take-profit values. Later, we tested the basic XGBClassifier setup and then enhanced the results by adding re-sampling methods. Our target classes, which include 0’s (neutral), 1’s (for long trades), and 2’s (for short trades), were imbalanced due to the trade execution timing. To address this imbalance, we employed re-sampling methods and performed hyper-optimization of the classifier model. Subsequently, we evaluated if the model performed better with other classifier models such as SVC, CatBoost, and LightGBM, in combination with LSTM and XGBoost. Finally, we concluded by analyzing the results and determining feature importance parameters to identify the most productive features.
“Hyper Optimized Algorithmic Strategy Vs/+ Machine Learning Models Part -3 (XGBoost Classifier , LGBM Classifier, CatBoost Classifier, SVC, LSTM with XGB and Multi level Hyper-optimization)” — Link
Stage 6:
In that stage, I utilized the CatBoostClassifier along with resampling and sample weights. I incorporated multiple time frame indicators such as volume, momentum, trend, and volatility into my model. After running the model, I performed ensembling techniques to enhance its overall performance. The results of my analysis showed a significant increase in profit from 54% to over 4600% during backtesting. Additionally, I highlighted the impressive performance metrics including recall, precision, accuracy, and F1 score, all exceeding 80% for each of the three trading classes (0 for neutral, 1 for long, and 2 for short trades).
“From 54% to a Staggering 4648%: Catapulting Cryptocurrency Trading with CatBoost Classifier, Machine Learning Model at Its Best” — Link
Stage 7:
In this stage, the ensemble method combining TCN and LSTM neural network models has demonstrated exceptional performance across various datasets, outperforming individual models and even surpassing buy and hold strategies. This underscores the effectiveness of ensemble learning in improving prediction accuracy and robustness.
“Bitcoin/BTC 4750%+ , Etherium/ETH 11,270%+ profit in 1023 days using Neural Networks, Algorithmic Trading Vs/+ Machine Learning Models Vs/+ Deep Learning Model Part — 4 (TCN, LSTM, Transformer with Ensemble Method)” — Link
Stage 8:
Experience the future of trading with VishvaAlgo v3.8. With its advanced features, unparalleled risk management capabilities, and ease of integration of ML and neural network models, VishvaAlgo is the ultimate choice for traders seeking consistent profits and peace of mind. Don’t miss out on this opportunity to revolutionize your trading journey.
Purchase Link: VishvaAlgo V3.8 Live Crypto Trading Using Machine Learning Model
“VishvaAlgo v3.0 — Revolutionize Your Live Cryptocurrency Trading system Enhanced with Machine Learning (Neural Network) Model. Live Profits Screenshots Shared” — Link
Youtube Link Explanation of VishvaAlgo v4.x Features — Link
get entire code and profitable algos @ https://patreon.com/pppicasso
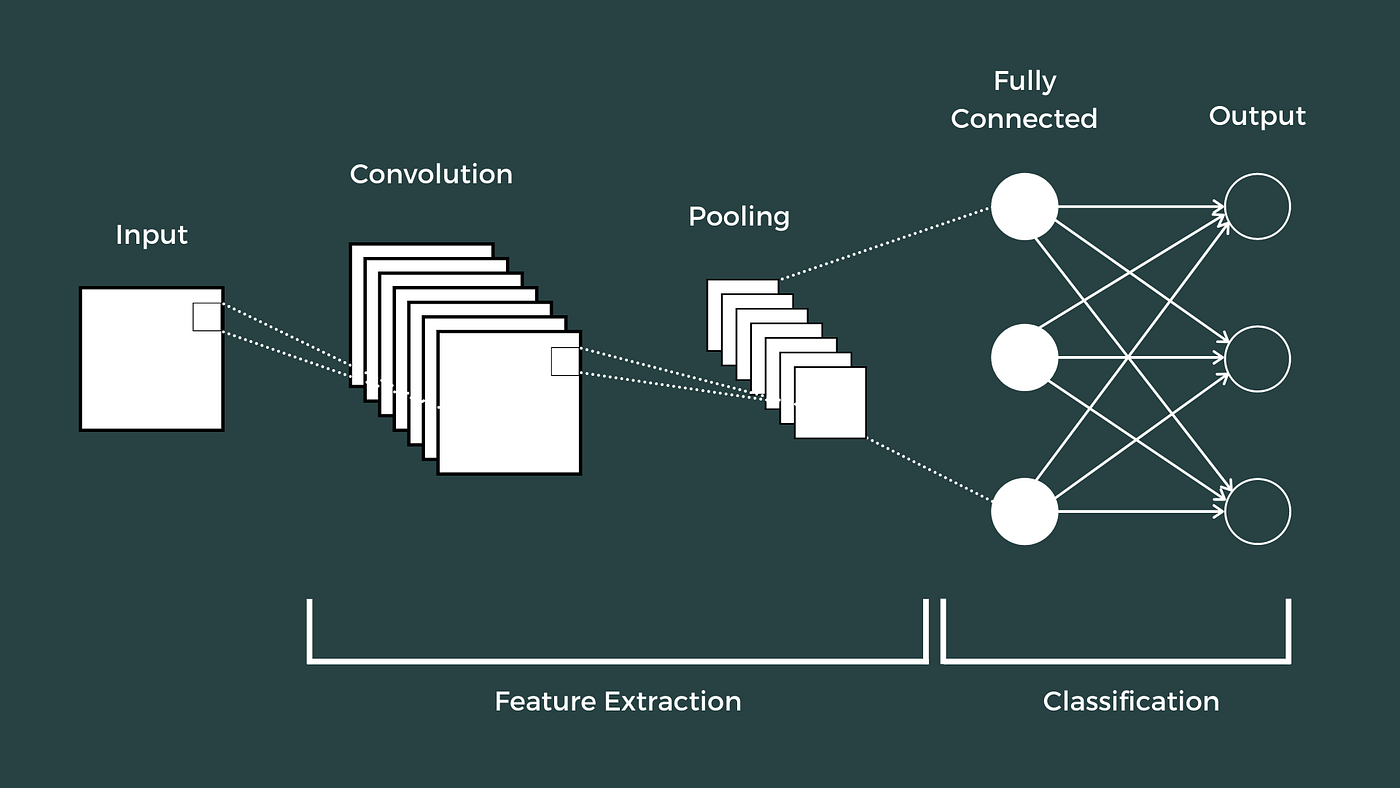
Introduction to CNNs and Time Series Classification
Convolutional Neural Networks (CNNs) are primarily designed for processing grid-like data, such as images and videos, where they have proven highly effective. CNNs work by applying convolutional filters that scan the input data and learn spatial hierarchies of features. Typically used in image and video processing, CNNs can also be adapted for time series data due to their ability to capture local patterns and trends.
CNNs for Image and Video Processing
- Image Processing: CNNs are used to identify objects, detect faces, and recognize patterns within images. They work by applying a series of convolutional layers, pooling layers, and fully connected layers to extract features and make predictions.
- Video Processing: In video data, CNNs can be used for tasks like action recognition and video classification. They process each frame as an image and can use temporal layers to capture the sequence of frames.
CNNs for Time Series Data
Despite their typical use in image and video processing, CNNs can be highly effective for time series classification. Here’s how:
- Feature Extraction: CNNs can extract temporal features from time series data, identifying patterns such as trends, seasonality, and anomalies.
- Local Pattern Recognition: The convolutional filters can capture local patterns within the time series data, which is crucial for financial data where short-term trends and fluctuations matter.
- Dimensionality Reduction: Pooling layers can reduce the dimensionality of the data, retaining the most important features while reducing computational complexity.
2D CNN for Multi-Class Classification on ETH Data
Data Description
- Asset: Ethereum (ETH)
- Time Frame: 15-minute intervals
- Rows: Over 100,000
- Features: 193+ (e.g., OHLCV, technical indicators)
Model Architecture and Training
- Input Shape: The input data for the model is structured in a 2D format, with the shape (number of samples, number of timesteps, number of features).
- Convolutional Layers: These layers apply convolutional filters across the input data to learn local temporal features.
x = Conv2D(filters=64, kernel_size=(3, 3), activation='relu')(inputs)
3. Pooling Layers: These layers reduce the dimensionality of the feature maps while retaining important information.
x = MaxPooling2D(pool_size=(2, 2))(x)
4. Dense Layers: Fully connected layers interpret the features extracted by the convolutional layers.
x = Flatten()(x) x = Dense(units=128, activation='relu')(x)
5. Output Layer: The final layer uses a softmax activation function to output probabilities for each class (neutral, long, short).
outputs = Dense(3, activation='softmax')(x)
Training the Model
The model is trained using labeled time series data, where each segment of the time series is labeled as 0 (neutral), 1 (long), or 2 (short).
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=50, batch_size=64, validation_split=0.2)Example Code
Here is a complete example of a 2D CNN for multi-class classification of ETH time series data:
import numpy as np
import keras
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split
# Simulate data
X = np.random.rand(100000, 15, 193, 1) # 100,000 samples, 15 timesteps, 193 features, 1 channel
y = np.random.randint(3, size=100000) # 100,000 labels (0, 1, 2)
# Convert labels to one-hot encoding
y = to_categorical(y, num_classes=3)
# Split data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Build model
inputs = Input(shape=(15, 193, 1))
x = Conv2D(filters=64, kernel_size=(3, 3), activation='relu')(inputs)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Flatten()(x)
x = Dense(units=128, activation='relu')(x)
x = Dropout(0.5)(x)
outputs = Dense(3, activation='softmax')(x)
model = Model(inputs=inputs, outputs=outputs)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Train model
model.fit(X_train, y_train, epochs=10, batch_size=64, validation_data=(X_val, y_val))Effectiveness of CNNs for Time Series Classification
- Pattern Recognition: CNNs can effectively capture and recognize patterns in time series data, making them suitable for financial market analysis.
- Speed: CNNs can process large datasets efficiently, which is crucial for high-frequency trading strategies.
- Accuracy: When properly tuned, CNNs can achieve high accuracy in predicting market movements, helping traders make informed decisions.
In summary, while CNNs are traditionally used for image and video processing, their ability to capture local patterns and reduce dimensionality makes them highly effective for time series classification in financial markets. This adaptability allows for robust models that can predict market movements, such as those in the cryptocurrency market, aiding in the classification of positions like long, short, and neutral.
The Whole code Explanation:
Youtube Link Explanation of VishvaAlgo v4.x Features — Link
get entire code and profitable algos @ https://patreon.com/pppicasso
# Remove Future Warnings
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
# Suppress PerformanceWarning
warnings.filterwarnings("ignore")
# General
import numpy as np
# Data Management
import pandas as pd
# Machine Learning
from catboost import CatBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import RandomizedSearchCV, cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.linear_model import LogisticRegression
# ensemble
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.ensemble import StackingClassifier
from sklearn.ensemble import VotingClassifier
#Sampling Methods
from imblearn.over_sampling import ADASYN
#Scaling
from sklearn.preprocessing import MinMaxScaler
# Binary Classification Specific Metrics
from sklearn.metrics import RocCurveDisplay as plot_roc_curve
# General Metrics
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import confusion_matrix, classification_report, roc_curve, roc_auc_score, accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import ConfusionMatrixDisplay
# Reporting
import matplotlib.pyplot as plt
from matplotlib.pylab import rcParams
from xgboost import plot_tree
#Backtesting
from backtesting import Backtest
from backtesting import Strategy
#hyperopt
from hyperopt import fmin, tpe, hp
from pandas_datareader.data import DataReader
import json
from datetime import datetime
import talib as ta
import ccxt
# from sklearn.model_selection import train_test_split
from sklearn.utils import class_weight
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
from keras.optimizers import Adam
# from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.ensemble import VotingClassifier
from hyperopt import fmin, tpe, hp, STATUS_OK, TrialsImport Statements (Lines 1–18):
- Warnings (Lines 1–4):
- These lines suppress warnings that might appear during execution. While this can be helpful for uninterrupted training, it’s generally recommended to address the warnings themselves for better debugging and understanding potential issues.
- General Libraries (Lines 5–7):
numpy (np): Provides numerical computing capabilities, often used for array operations and mathematical functions. Not directly applicable to article writing.pandas (pd): Used for data manipulation, analysis, and visualization. Essential for working with structured data in articles (e.g., tables, charts).- Machine Learning Libraries (Lines 8–13):
catboost(not explicitly imported here): Provides a powerful gradient boosting library for machine learning tasks. Not directly relevant to article writing unless you're discussing specific machine learning algorithms.scikit-learn(various submodules): A comprehensive machine learning library. Parts might be useful for illustrating concepts or comparing approaches in articles:train_test_split: Splits data into training and testing sets for model evaluation.RandomizedSearchCV,cross_val_score,RepeatedStratifiedKFold: Techniques for hyperparameter tuning and model evaluation (cross-validation).LogisticRegression: A linear classification model. Potentially relevant if discussing classification algorithms.- Ensemble Methods (Lines 14–16):
scikit-learn(submodules): Techniques for combining multiple models to improve performance. Not directly applicable to article writing.- Sampling Methods (Line 17):
imblearn: Provides tools for handling imbalanced datasets (where classes have unequal sizes). Not typically used in article writing itself.- Scaling (Line 18):
scikit-learn: Techniques for normalizing or standardizing data (often necessary for machine learning models). Can be relevant in articles to explain data preprocessing steps.
Metrics (Lines 19–33):
- Binary Classification Metrics (Lines 19–21):
scikit-learn: Used to evaluate the performance of classification models, particularly for binary classification (two classes). Not directly applicable to article writing unless discussing model evaluation metrics.- General Metrics (Lines 22–33):
scikit-learn: Various metrics for evaluating model performance across different classification tasks. Can be useful in articles to explain how models are assessed:accuracy_score: Proportion of correct predictions.precision_score: Proportion of true positives among predicted positives.confusion_matrix: Visualization of how many instances were classified correctly or incorrectly for each class.classification_report: Detailed report on model performance, including precision, recall, F1-score, and support for each class.roc_curve,roc_auc_score: Measures for assessing the Receiver Operating Characteristic (ROC) curve, which helps evaluate a model's ability to discriminate between classes.
Reporting (Lines 34–36):
matplotlib.pyplot (plt): Used for creating visualizations like charts and graphs. Essential for presenting data and model results in articles.
Backtesting (Lines 37–38):
backtesting: Library for backtesting trading strategies. Not relevant to article writing unless discussing financial applications of machine learning.
Hyperparameter Optimization (Lines 39–42):
hyperopt: Library for hyperparameter tuning (finding the best settings for machine learning models). Not directly applicable to article writing.
Data Retrieval (Line 43):
pandas_datareader: Facilitates data retrieval from various financial data sources. Not typically used in article writing itself.
Other Imports (Lines 44–50):
json: For working with JSON data format (not directly used here).datetime: For working with date and time objects. Can be useful in articles for handling time-series data.talib: Technical analysis library for financial markets (not directly used here).ccxt(not explicitly imported here): Library for interacting with cryptocurrency exchanges (not relevant to article writing).
Context:
- Each library and module is imported with a specific purpose, such as data manipulation, machine learning, evaluation, visualization, backtesting, hyperparameter optimization, etc.
- These libraries and modules will be used throughout the code for various tasks like data preprocessing, model training, evaluation, optimization, and visualization.
# Define the path to your JSON file
file_path = './ETH_USDT_USDT-15m-futures.json'
# Open the file and read the data
with open(file_path, "r") as f:
data = json.load(f)
df = pd.DataFrame(data)
# Extract the OHLC data (adjust column names as needed)
# ohlc_data = df[["date","open", "high", "low", "close", "volume"]]
df.rename(columns={0: "Date", 1: "Open", 2: "High",3: "Low", 4: "Adj Close", 5: "Volume"}, inplace=True)
# Convert timestamps to datetime objects
df["Date"] = pd.to_datetime(df['Date'] / 1000, unit='s')
df.set_index("Date", inplace=True)
# Format the date index
df.index = df.index.strftime("%m-%d-%Y %H:%M")
df['Close'] = df['Adj Close']
# print(df.dropna(), df.describe(), df.info())
data = df
dataTo analyze historical cryptocurrency futures data, we can first load the data from a JSON file. The provided code demonstrates how to use Python’s json library to parse the JSON content into a dictionary. We then convert this dictionary into a pandas DataFrame for easier manipulation. The DataFrame is cleaned and transformed by renaming columns, converting timestamps to datetime objects, setting the date as the index, and formatting the date display for better readability.
Here’s the step-by-step explanation of the code:
1. Loading JSON Data:
- The code defines a file path (
file_path) to a JSON file containing cryptocurrency data (presumably in the format of Open-High-Low-Close-Volume for Ethereum futures contracts traded with USDT). - It opens the file for reading (
with open(file_path, "r") as f:) and usesjson.load(f)to parse the JSON content into a Python dictionary (data).
2. Converting to DataFrame:
- The code creates a pandas DataFrame (
df) from the loaded dictionary (data). A DataFrame is a tabular data structure similar to a spreadsheet, making it easier to work with and analyze the data.
3. Data Cleaning and Transformation:
- This part assumes the JSON data has columns with numerical indices (0, 1, 2, etc.) instead of meaningful names. It renames these columns to more descriptive labels (
"Date","Open","High","Low","Adj Close","Volume") usingdf.rename(columns={...}, inplace=True). - It converts the
"Date"column from timestamps (likely in milliseconds since some epoch) to datetime objects usingpd.to_datetime(). This makes it easier to work with dates and perform time-based operations. - The code sets the
"Date"column as the index of the DataFrame usingdf.set_index("Date", inplace=True). This allows you to efficiently access and filter data based on dates. - It formats the date index using
df.index.strftime("%m-%d-%Y %H:%M")to display dates in a more readable format (e.g., "05-14-2024 16:35"). - Finally, it assigns the column named
"Adj Close"(assuming it represents the adjusted closing price) to a variable named"Close"for potentially clearer reference.
# Assuming you have a DataFrame named 'df' with columns 'Open', 'High', 'Low', 'Close', 'Adj Close', and 'Volume'
target_prediction_number = 2
time_periods = [6, 8, 10, 12, 14, 16, 18, 22, 26, 33, 44, 55]
name_periods = [6, 8, 10, 12, 14, 16, 18, 22, 26, 33, 44, 55]
df = data.copy()
new_columns = []
for period in time_periods:
for nperiod in name_periods:
df[f'ATR_{period}'] = ta.ATR(df['High'], df['Low'], df['Close'], timeperiod=period)
df[f'EMA_{period}'] = ta.EMA(df['Close'], timeperiod=period*2)
df[f'RSI_{period}'] = ta.RSI(df['Close'], timeperiod=period*0.5)
df[f'VWAP_{period}'] = ta.SUM(df['Volume'] * (df['High'] + df['Low'] + df['Close']) / 3, timeperiod=period) / ta.SUM(df['Volume'], timeperiod=period)
df[f'ROC_{period}'] = ta.ROC(df['Close'], timeperiod=period)
df[f'KC_upper_{period}'] = ta.EMA(df['High'], timeperiod=period*2)
df[f'KC_middle_{period}'] = ta.EMA(df['Low'], timeperiod=period*2)
df[f'Donchian_upper_{period}'] = ta.MAX(df['High'], timeperiod=period)
df[f'Donchian_lower_{period}'] = ta.MIN(df['Low'], timeperiod=period)
macd, macd_signal, _ = ta.MACD(df['Close'], fastperiod=(period + 12), slowperiod=(period + 26), signalperiod=(period + 9))
df[f'MACD_{period}'] = macd
df[f'MACD_signal_{period}'] = macd_signal
bb_upper, bb_middle, bb_lower = ta.BBANDS(df['Close'], timeperiod=period*0.5, nbdevup=2, nbdevdn=2)
df[f'BB_upper_{period}'] = bb_upper
df[f'BB_middle_{period}'] = bb_middle
df[f'BB_lower_{period}'] = bb_lower
df[f'EWO_{period}'] = ta.SMA(df['Close'], timeperiod=(period+5)) - ta.SMA(df['Close'], timeperiod=(period+35))
df["Returns"] = (df["Adj Close"] / df["Adj Close"].shift(target_prediction_number)) - 1
df["Range"] = (df["High"] / df["Low"]) - 1
df["Volatility"] = df['Returns'].rolling(window=target_prediction_number).std()
# Volume-Based Indicators
df['OBV'] = ta.OBV(df['Close'], df['Volume'])
df['ADL'] = ta.AD(df['High'], df['Low'], df['Close'], df['Volume'])
# Momentum-Based Indicators
df['Stoch_Oscillator'] = ta.STOCH(df['High'], df['Low'], df['Close'])[0]
# Calculate the Elliott Wave Oscillator (EWO)
#df['EWO'] = ta.SMA(df['Close'], timeperiod=5) - ta.SMA(df['Close'], timeperiod=35)
# Volatility-Based Indicators
# df['ATR'] = ta.ATR(df['High'], df['Low'], df['Close'], timeperiod=14)
# df['BB_upper'], df['BB_middle'], df['BB_lower'] = ta.BBANDS(df['Close'], timeperiod=20, nbdevup=2, nbdevdn=2)
# df['KC_upper'], df['KC_middle'] = ta.EMA(df['High'], timeperiod=20), ta.EMA(df['Low'], timeperiod=20)
# df['Donchian_upper'], df['Donchian_lower'] = ta.MAX(df['High'], timeperiod=20), ta.MIN(df['Low'], timeperiod=20)
# Trend-Based Indicators
# df['MA'] = ta.SMA(df['Close'], timeperiod=20)
# df['EMA'] = ta.EMA(df['Close'], timeperiod=20)
df['PSAR'] = ta.SAR(df['High'], df['Low'], acceleration=0.02, maximum=0.2)
# Set pandas option to display all columns
pd.set_option('display.max_columns', None)
# Displaying the calculated indicators
print(df.tail())
df.dropna(inplace=True)
print("Length: ", len(df))
dfYoutube Link Explanation of VishvaAlgo v4.x Features — Link
get entire code and profitable algos @ https://patreon.com/pppicasso
This code demonstrates the calculation of various technical indicators using the talib library. The code iterates through different time periods to compute indicators like Average True Range (ATR), Exponential Moving Average (EMA), Relative Strength Index (RSI), and several others. Additionally, it calculates features like returns, range, and volatility to potentially use as input features for machine learning models.
1. Technical Indicator Calculations:
- The code iterates through two lists,
time_periodsandname_periods(which seem to have the same values here). This might be a placeholder for using different sets of periods for the indicators in the future. - Within the loops, it calculates numerous technical indicators for each specified time period (
period) usingtalibfunctions: - Average True Range (ATR): Measures market volatility (
df[f'ATR_{period}']). - Exponential Moving Average (EMA): Calculates EMAs with a period twice the loop’s
period(df[f'EMA_{period}']). - Relative Strength Index (RSI): Calculates RSI with a period half the loop’s
period(df[f'RSI_{period}']). - Volume-Weighted Average Price (VWAP): Calculates VWAP for the
period(df[f'VWAP_{period}']). - Rate of Change (ROC): Calculates ROC for the
period(df[f'ROC_{period}']). - Keltner Channels (KC): Calculates upper and middle bands based on EMAs of highs and lows (
df[f'KC_upper_{period}'],df[f'KC_middle_{period}']). - Donchian Channels: Calculates upper and lower bands based on maximum and minimum highs/lows within the
period(df[f'Donchian_upper_{period}'],df[f'Donchian_lower_{period}']). - Moving Average Convergence Divergence (MACD): Calculates MACD and its signal line for the
period(df[f'MACD_{period}'],df[f'MACD_signal_{period}']). - Bollinger Bands (BB): Calculates upper, middle, and lower bands for the
period(df[f'BB_upper_{period}'],df[f'BB_middle_{period}'],df[f'BB_lower_{period}']). - Elliott Wave Oscillator (EWO): Calculates EWO for the
period(df[f'EWO_{period}']). - Target Prediction and Feature Engineering:
- The code defines a
target_prediction_number(presumably the number of periods ahead you aim to predict). - It calculates “Returns” as the percentage change in adjusted close prices over the
target_prediction_numberperiods (df["Returns"]). - It calculates “Range” as the difference between high and low prices divided by the low price (
df["Range"]). - It calculates “Volatility” as the rolling standard deviation of returns over the
target_prediction_numberperiods (df["Volatility"]). - Additional Indicators:
- The code calculates On-Balance Volume (OBV) and Accumulation Distribution Line (ADL) using
talibfunctions (df['OBV'],df['ADL']). - It calculates the Stochastic Oscillator using
talib(df['Stoch_Oscillator']). - It calculates the Parabolic Stop and Reversal (PSAR) using
talib(df['PSAR']).
Data- Preprocessing — Setting up “Target” value for estimating future predictive values
# Target flexible way
pipdiff_percentage = 0.01 # 1% (0.01) of the asset's price for TP
SLTPRatio = 2.0 # pipdiff/Ratio gives SL
def mytarget(barsupfront, df1):
length = len(df1)
high = list(df1['High'])
low = list(df1['Low'])
close = list(df1['Close'])
open_ = list(df1['Open']) # Renamed 'open' to 'open_' to avoid conflict with Python's built-in function
trendcat = [None] * length
for line in range(0, length - barsupfront - 2):
valueOpenLow = 0
valueOpenHigh = 0
for i in range(1, barsupfront + 2):
value1 = open_[line + 1] - low[line + i]
value2 = open_[line + 1] - high[line + i]
valueOpenLow = max(value1, valueOpenLow)
valueOpenHigh = min(value2, valueOpenHigh)
if (valueOpenLow >= close[line + 1] * pipdiff_percentage) and (
-valueOpenHigh <= close[line + 1] * pipdiff_percentage / SLTPRatio):
trendcat[line] = 2 # -1 downtrend
break
elif (valueOpenLow <= close[line + 1] * pipdiff_percentage / SLTPRatio) and (
-valueOpenHigh >= close[line + 1] * pipdiff_percentage):
trendcat[line] = 1 # uptrend
break
else:
trendcat[line] = 0 # no clear trend
return trendcatThis code defines a function mytarget that attempts to identify potential trends and set target values accordingly. It calculates the difference between the open price and upcoming highs/lows within a specified timeframe (barsupfront). Based on these differences and thresholds defined by pipdiff_percentage and SLTPRatio, the function classifies the trend as uptrend, downtrend, or no clear trend. These classifications could then be used to set target buy/sell prices in a trading strategy.
Here’s the breakdown of the code provided:
The provided code defines a function mytarget that aims to set target values (presumably for buying and selling) based on a trend classification. Here's a breakdown of its functionality:
Parameters:
barsupfront(integer): The number of bars to look ahead from the current bar for trend classification.df1(pandas DataFrame): The DataFrame containing OHLC (Open, High, Low, Close) prices.
Function Logic:
- Initialization:
- It retrieves the length of the DataFrame (
length). - It extracts lists of high, low, close, and open prices (
high,low,close,open_). Note thatopenis renamed toopen_to avoid conflicts with Python's built-inopenfunction. - It initializes a list
trendcatwithlengthelements, all set toNone, which will eventually hold the trend category (uptrend, downtrend, or no trend) for each bar.
2. Trend Classification Loop:
- The code iterates through the DataFrame, starting from the
barsupfront-th bar to the second-last bar (length - barsupfront - 2). - Inside the loop:
- It calculates two values:
valueOpenLow: Maximum difference between the open price at the current bar and the low prices in the nextbarsupfront + 1bars.valueOpenHigh: Minimum difference between the open price at the current bar and the high prices in the nextbarsupfront + 1bars.- It checks these values against thresholds based on
pipdiff_percentage(a percentage of the asset's price) andSLTPRatio: - If
valueOpenLowis greater than or equal toclose[line + 1] * pipdiff_percentage(meaning the open is significantly lower than some of the upcoming lows) AND-valueOpenHighis less than or equal toclose[line + 1] * pipdiff_percentage / SLTPRatio(meaning the open is not significantly higher than some of the upcoming highs), it classifies the trend as downtrend (trendcat[line]is set to 2). - Conversely, if
valueOpenLowis less than or equal toclose[line + 1] * pipdiff_percentage / SLTPRatio(meaning the open is significantly higher than some of the upcoming lows) AND-valueOpenHighis greater than or equal toclose[line + 1] * pipdiff_percentage(meaning the open is not significantly lower than some of the upcoming highs), it classifies the trend as uptrend (trendcat[line]is set to 1). - If neither condition is met, it marks no clear trend (
trendcat[line]remains0).
3. Return:
- The function returns the
trendcatlist containing the trend classification for each bar (except the firstbarsupfrontbars). - pen_spark
#!!! pitfall one category high frequency
df['Target'] = mytarget(2, df)
df['Target'] = df['Target'].shift(1)
#df.tail(20)
df.replace([np.inf, -np.inf], np.nan, inplace=True)
df.dropna(axis=0, inplace=True)
# Convert columns to integer type
df = df.astype(int)
#df['Target'] = df['Target'].astype(int)
df['Target'].hist()
count_of_twos_target = df['Target'].value_counts().get(2, 0)
count_of_zeros_target = df['Target'].value_counts().get(0, 0)
count_of_ones_target = df['Target'].value_counts().get(1, 0)
percent_of_zeros_over_ones_and_twos = (100 - (count_of_zeros_target/ (count_of_zeros_target + count_of_ones_target + count_of_twos_target))*100)
print(f' count_of_zeros = {count_of_zeros_target}\n count_of_twos_target = {count_of_twos_target}\n count_of_ones_target={count_of_ones_target}\n percent_of_zeros_over_ones_and_twos = {round(percent_of_zeros_over_ones_and_twos,2)}%')
After assigning trend classifications (Target) based on the mytarget function, the code performs data cleaning by handling infinities and removing rows with missing values. It then analyzes the distribution of target values using a histogram and calculates the proportion of bars classified as each trend category. This helps assess the balance between clear uptrends, downtrends, and periods with no clear trend in the data.
1. Assigning Target Values and Shifting:
- The code assigns the output of
mytarget(2, df)(presumably trend classifications) to the'Target'column (df['Target'] = mytarget(2, df)). - It then shifts the
'Target'values by one position upwards (df['Target'] = df['Target'].shift(1)) because the trend classification is based on future price movements. This means the target value for barnis based on the trend classification for barn-1.
2. Handling Infinities and Missing Values:
- The code replaces positive and negative infinity (
np.infand-np.inf) withNaN(Not a Number) values in the DataFrame (df.replace([np.inf, -np.inf], np.nan, inplace=True)). This is necessary because some mathematical operations cannot handle infinities. - It then removes rows with missing values (
NaN) from the DataFrame (df.dropna(axis=0, inplace=True)) to ensure clean data for further analysis.
3. Converting Data Types (Commented Out):
- The line
df = df.astype(int)is commented out. This line would attempt to convert all columns in the DataFrame to integers. However, since the'Target'column likely contains categorical values (1, 2, or 0), converting it to integer might not be meaningful. You'd typically only convert numerical columns to integers if necessary for calculations.
4. Analyzing Target Distribution:
- The code plots a histogram of the
'Target'column (df['Target'].hist()). This helps visualize the distribution of target values (uptrend, downtrend, or no trend) across the data. - It then calculates the counts of each target value (1, 2, and 0) using
value_counts(). - Finally, it calculates the percentage of bars classified as “no trend” relative to the sum of bars classified as uptrend and downtrend (
percent_of_zeros_over_ones_and_twos). This provides insights into the balance between clear trends and unclear trends in the data.
This code segment effectively calculates target categories based on predefined criteria and provides insights into the distribution of these categories within the dataset.
Checking if the above Code is Giving Best Possible Returns for the “Target” Data Created:
# Check for NaN values:
has_nan = df['Target'].isnull().values.any()
print("NaN values present:", has_nan)
# Check for infinite values:
has_inf = df['Target'].isin([np.inf, -np.inf]).values.any()
print("Infinite values present:", has_inf)
# Count the number of NaN and infinite values:
nan_count = df['Target'].isnull().sum()
inf_count = (df['Target'] == np.inf).sum() + (df['Target'] == -np.inf).sum()
print("Number of NaN values:", nan_count)
print("Number of infinite values:", inf_count)
# Get the indices of NaN and infinite values:
nan_indices = df['Target'].index[df['Target'].isnull()]
inf_indices = df['Target'].index[df['Target'].isin([np.inf, -np.inf])]
print("Indices of NaN values:", nan_indices)
df['Target']
df = df.reset_index(inplace=False)
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
def SIGNAL(df):
return df['Target']
from backtesting import Strategy
class MyCandlesStrat(Strategy):
def init(self):
super().init()
self.signal1 = self.I(SIGNAL, self.data)
def next(self):
super().next()
if self.signal1 == 1:
sl_pct = 0.025 # 2.5% stop-loss
tp_pct = 0.025 # 2.5% take-profit
sl_price = self.data.Close[-1] * (1 - sl_pct)
tp_price = self.data.Close[-1] * (1 + tp_pct)
self.buy(sl=sl_price, tp=tp_price)
elif self.signal1 == 2:
sl_pct = 0.025 # 2.5% stop-loss
tp_pct = 0.025 # 2.5% take-profit
sl_price = self.data.Close[-1] * (1 + sl_pct)
tp_price = self.data.Close[-1] * (1 - tp_pct)
self.sell(sl=sl_price, tp=tp_price)
bt = Backtest(df, MyCandlesStrat, cash=100000, commission=.001, exclusive_orders = True)
stat = bt.run()
stat
- Checking for Missing and Infinite Values:
- The code checks for the presence of
NaN(Not a Number) and infinite values in the'Target'column (df['Target']). - It then counts the number of occurrences and retrieves the indices of these values.
- These checks are crucial because backtesting libraries typically cannot handle missing or infinite values in signals.
2. Backtesting Framework Setup:
- The code defines a function
SIGNAL(df)that simply returns the'Target'column values. This function essentially provides the buy/sell signals based on the target classifications (1 for uptrend buy, 2 for downtrend sell). - It imports the
Strategyclass from thebacktestinglibrary. - It defines a custom strategy class
MyCandlesStratthat inherits fromStrategy. - The
initmethod initializes an indicator namedsignal1that holds the target values using theIfunction (presumably frombacktesting). - The
nextmethod defines the trading logic: - If the
signal1is 1 (uptrend), it places a buy order with a stop-loss and take-profit based on percentages of the closing price. - If the
signal1is 2 (downtrend), it places a sell order with a stop-loss and take-profit based on percentages of the closing price.
3. Backtesting and Evaluation:
- The code creates a
Backtestobject using thebacktestinglibrary. It provides the DataFrame (df), the strategy class (MyCandlesStrat), initial capital (cash), commission rate (commission), and setsexclusive_orderstoTrue(potentially to prevent overlapping orders). - It runs the backtest using the
bt.run()method and stores the results in thestatvariable.
Does this code definitively determine the effectiveness of the target values?
No, this code doesn’t definitively determine the effectiveness of the target values. Here’s why:
- Parameter Optimization: The stop-loss and take-profit percentages (
sl_pctandtp_pct) are fixed in the code. Optimizing these parameters for the specific strategy and market conditions could potentially improve performance. - Single Backtest Run: Running the backtest only once doesn’t account for the inherent randomness in financial markets. Ideally, you’d run the backtest multiple times with different random seeds to assess its robustness.
How to improve the code for target evaluation?
- Calculate Performance Metrics: Modify the code to calculate and print relevant performance metrics like Sharpe Ratio, drawdown, and total profit after the backtest run.
- Optimize Stop-Loss and Take-Profit: Implement a parameter optimization process to find the best stop-loss and take-profit values for the strategy using the target signals.
- Multiple Backtest Runs: Run the backtest with different random seeds (e.g., using a loop) and analyze the distribution of performance metrics to assess the strategy’s consistency.
By incorporating these improvements, wecan gain a more comprehensive understanding of how well the target values from the mytarget function perform in a backtesting framework. Remember, backtesting results are not guarantees of future performance, so real-world testing with a smaller capital allocation is essential before deploying a strategy with real money.
Scaling and splitting the dataframe for training and testing:
scaler = MinMaxScaler(feature_range=(0,1))
df_model = df.copy()
# Split into Learning (X) and Target (y) Data
X = df_model.iloc[:, : -1]
y = df_model.iloc[:, -1]
X_scaled = scaler.fit_transform(X)
# Define a function to reshape the data
def reshape_data(data, time_steps):
samples = len(data) - time_steps + 1
reshaped_data = np.zeros((samples, time_steps, data.shape[1]))
for i in range(samples):
reshaped_data[i] = data[i:i + time_steps]
return reshaped_data
# Reshape the scaled X data
time_steps = 1 # Adjust the number of time steps as needed
X_reshaped = reshape_data(X_scaled, time_steps)
# Now X_reshaped has the desired three-dimensional shape: (samples, time_steps, features)
# Each sample contains scaled data for a specific time window
# Align y with X_reshaped by discarding excess target values
y_aligned = y[time_steps - 1:] # Discard the first (time_steps - 1) target values
X = X_reshaped
y = y_aligned
print(len(X),len(y))
# Split data into train and test sets (considering time series data)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False)1. Data Preparation:
- Copying Data: It creates a copy of the original DataFrame (
df_model = df.copy()) to avoid modifying the original data.
2. Splitting Features and Target:
- Separating Features (X) and Target (y): It separates the features (all columns except the last) and the target variable (the last column) using slicing (
X = df_model.iloc[:, : -1],y = df_model.iloc[:, -1]).
3. Scaling Features:
- MinMaxScaler: It creates a
MinMaxScalerobject to scale the features between 0 and 1 (scaler = MinMaxScaler(feature_range=(0,1))). This can be helpful for some machine learning algorithms that work better with normalized data. - Scaling X: It scales the feature data (
X) using thefit_transformmethod of the scaler (X_scaled = scaler.fit_transform(X)).
4. Reshaping Data (Windowing):
- Reshape Function: It defines a function
reshape_datathat takes the data and the number of time steps (time_steps) as input. - This function iterates through the data with a sliding window of
time_stepsand creates a new 3D array (reshaped_data). - Each element in the new array represents a sample, containing a sequence of
time_stepsdata points for each feature. - Reshaping Scaled X: It defines the number of time steps (
time_steps) and reshapes the scaled feature data (X_scaled) using thereshape_datafunction (X_reshaped = reshape_data(X_scaled, time_steps)). - This step transforms the data into a format suitable for time series forecasting models that require sequences of past observations to predict future values.
5. Aligning Target with Reshaped Data:
- Discarding Excess Target Values: Since the reshaped data (
X_reshaped) considers a window oftime_steps, the corresponding target values need an adjustment. It discards the firsttime_steps - 1target values fromyto align with the reshaped data (y_aligned = y[time_steps - 1:]).
6. Final Splitting (Train-Test):
- Train-Test Split: It splits the reshaped features (
X) and aligned target (y) into training and testing sets usingtrain_test_splitfrom scikit-learn (X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False)). - It sets
test_size=0.3to allocate 30% of the data for testing andshuffle=Falsebecause shuffling data in time series can disrupt the temporal order.
Overall, this code effectively addresses key aspects of data preparation for time series forecasting models:
- Scaling features to a common range can improve model performance for some algorithms.
- Reshaping data into a 3D structure with time steps allows models to learn from sequences of past observations.
- Aligning the target variable with the reshaped data ensures the model predicts for the correct time steps.
- Splitting data into training and testing sets with
shuffle=Falsepreserves the temporal order for time series forecasting.
Additional Considerations:
- The choice of scaler (MinMaxScaler, StandardScaler, etc.) might depend on the specific model and data characteristics.
- You might explore different window sizes (
time_steps) to see how they affect model performance. - Techniques like stationarity checks and differencing might be necessary for certain time series data before applying these steps.
2D CNN Model Manual Optimization

from sklearn.utils.class_weight import compute_class_weight
from keras import backend as K
def build_model(hp):
inputs = Input(shape=(X_train.shape[1], X_train.shape[2], 1))
x = Conv2D(hp.Int('conv_units', min_value=16, max_value=64, step=16), (5, 5), padding='same', activation='relu')(inputs)
x = MaxPooling2D(pool_size=(2, 2), padding='same')(x)
x = Dense(units=hp.Int('dense_units', min_value=100, max_value=300, step=50), activation='relu')(x)
x = Dropout(hp.Float('dropout_rate', min_value=0.1, max_value=0.5, step=0.1))(x)
x = Flatten()(x)
x = Dense(units=hp.Int('dense_units', min_value=100, max_value=300, step=50), activation='relu')(x)
outputs = Dense(3, activation='softmax')(x)
model = Model(inputs=inputs, outputs=outputs)
optimizer = Adam(learning_rate=hp.Choice('learning_rate', values=[1e-2, 1e-3, 1e-4]))
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy', Precision(), Recall()])
return model
tuner = kt.Hyperband(
build_model,
objective=kt.Objective("val_recall", direction="max"),
max_epochs=20,
factor=3,
directory='my_dir',
project_name='hyperopt_cnn'
)
tuner.search(X_train, y_train_one_hot, epochs=10, validation_split=0.2)
# Get the best hyperparameters
best_hps = tuner.get_best_hyperparameters(num_trials=1)[0]
# Calculate class weights to handle class imbalance
class_weights = compute_class_weight('balanced', classes=np.unique(y_train), y=y_train)
class_weight_dict = dict(enumerate(class_weights))
# Build the model with the best hyperparameters
best_cnn_model = tuner.hypermodel.build(best_hps)
# Fit the model to the training data with best hyperparameters
# best_cnn_model.fit(X_train, y_train_one_hot, epochs=100, batch_size=24, validation_split=0.2, verbose=1, class_weight=class_weight_dict)
best_cnn_model.fit(X_train, y_train_one_hot, epochs=100, batch_size=18, validation_split=0.2, verbose=1)
This code defines and trains a 2D CNN-based model for classifying ETH price movements into three categories: neutral (0), long (1), and short (2). Here’s a breakdown:
Importing Libraries
from sklearn.utils.class_weight import compute_class_weight
from keras import backend as K
import keras_tuner as kt
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, Dense, Dropout, Flatten
from keras.optimizers import Adam
from keras.metrics import Precision, Recall
import numpy as np- compute_class_weight: Computes weights for classes to handle imbalanced datasets.
- keras.backend: Provides backend functions for operations.
- keras_tuner: Helps in hyperparameter tuning of models.
- Model: Used to create a Keras model.
- Layers: Various layers used to build the CNN model.
- Adam: The optimizer used to compile the model.
- Metrics: Precision and Recall metrics used to evaluate the model.
Building the Model
def build_model(hp):
inputs = Input(shape=(X_train.shape[1], X_train.shape[2], 1))
x = Conv2D(hp.Int('conv_units', min_value=16, max_value=64, step=16), (5, 5), padding='same', activation='relu')(inputs)
x = MaxPooling2D(pool_size=(2, 2), padding='same')(x)
x = Dense(units=hp.Int('dense_units', min_value=100, max_value=300, step=50), activation='relu')(x)
x = Dropout(hp.Float('dropout_rate', min_value=0.1, max_value=0.5, step=0.1))(x)
x = Flatten()(x)
x = Dense(units=hp.Int('dense_units', min_value=100, max_value=300, step=50), activation='relu')(x)
outputs = Dense(3, activation='softmax')(x)
model = Model(inputs=inputs, outputs=outputs)
optimizer = Adam(learning_rate=hp.Choice('learning_rate', values=[1e-2, 1e-3, 1e-4]))
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy', Precision(), Recall()])
return model- inputs: Input layer accepting data with shape
(number_of_timesteps, number_of_features, 1). - Conv2D: Convolutional layer with filters determined by hyperparameters (
hp.Int). It extracts local patterns. - MaxPooling2D: Pooling layer to reduce the spatial dimensions.
- Dense: Fully connected layers to interpret the extracted features.
- Dropout: Regularization technique to prevent overfitting.
- Flatten: Converts the 2D matrix to a 1D vector for the dense layers.
- outputs: Final output layer with a softmax activation function for multi-class classification.
Hyperparameter Tuning
tuner = kt.Hyperband(
build_model,
objective=kt.Objective("val_recall", direction="max"),
max_epochs=20,
factor=3,
directory='my_dir',
project_name='hyperopt_cnn'
)- Hyperband: A Keras Tuner algorithm for hyperparameter tuning.
- objective: The metric to optimize during tuning (validation recall in this case).
- max_epochs: Maximum number of epochs to train.
- factor: Reduction factor for early stopping.
- directory/project_name: Where to save the tuning results.
Running the Tuner
tuner.search(X_train, y_train_one_hot, epochs=10, validation_split=0.2)- search: Runs the hyperparameter tuning process on the training data.
Get Best Hyperparameters
best_hps = tuner.get_best_hyperparameters(num_trials=1)[0]- Retrieves the best hyperparameters identified during tuning.
Compute Class Weights
class_weights = compute_class_weight('balanced', classes=np.unique(y_train), y=y_train)
class_weight_dict = dict(enumerate(class_weights))- compute_class_weight: Balances the classes by computing weights inversely proportional to their frequencies.
- class_weight_dict: Dictionary of class weights.
Build and Train the Model with Best Hyperparameters
best_cnn_model = tuner.hypermodel.build(best_hps)
best_cnn_model.fit(X_train, y_train_one_hot, epochs=100, batch_size=18, validation_split=0.2, verbose=1)- build: Builds the model with the best hyperparameters.
- fit: Trains the model on the training data.
Why 2D CNN Might be Better than 1D CNN for This Task
Feature Interactions:
- 2D CNN: Can capture interactions between different features over time. This is crucial for time series data with multiple features, as it can learn complex patterns.
- 1D CNN: Typically captures temporal patterns within a single feature or one-dimensional sequence of data.
Spatial Relationships:
- 2D CNN: More effective in understanding spatial relationships between features, which can be valuable when multiple related features are present.
- 1D CNN: Focuses on one-dimensional sequences, which may not capture interactions between multiple features as effectively.
Dimensionality Reduction:
- 2D CNN: Pooling layers can reduce the dimensions more efficiently by considering spatial context, leading to better generalization.
- 1D CNN: May require more layers or parameters to achieve similar dimensionality reduction, potentially increasing complexity.
Pattern Recognition:
- 2D CNN: Can detect complex patterns by applying filters across two dimensions (time and features), which is beneficial for multi-feature time series data.
- 1D CNN: Limited to recognizing patterns in one dimension, which may not be sufficient for complex multi-feature datasets.
Conclusion
The given code sets up a 2D CNN model with hyperparameter tuning using Keras Tuner. The model is designed to handle multi-class classification for time series data of cryptocurrencies. By leveraging 2D CNNs, the model can capture intricate patterns across both time and features, potentially leading to more accurate and robust predictions compared to 1D CNNs. The use of hyperparameter tuning ensures that the model is optimized for the given task, further enhancing its performance.
Additional Notes:
- The provided code might require adjustments based on your specific data and desired performance. Hyperparameter tuning (e.g., number of units, dropout rate, learning rate) is crucial for optimizing the model.
- Consider using techniques like normalization or standardization for your features to improve model performance.
Further Exploration:
- Experiment with different hyperparameters (number of layers, units, attention heads) to find the best configuration for your data and task.
- Consider incorporating additional features like technical indicators or fundamental data points to potentially improve the model’s prediction accuracy.
- Evaluate the model’s performance using various metrics like precision, recall, F1-score, or a custom metric based on your specific trading strategy.
Real-World Considerations:
- Financial markets are complex and influenced by various factors. Past price movements don’t guarantee future performance.
- Use the model predictions as a guide, not a definitive signal. Consider risk management strategies and other factors before making trading decisions.
- Backtest your model on historical data to assess its performance in different market conditions.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
# # Reshape X_train and X_test back to their original shapes
# X_train_original_shape = X_train.reshape(X_train.shape[0], -1)
# X_test_original_shape = X_test.reshape(X_test.shape[0], -1)
# X_test_reshaped = X_test_original_shape.reshape(-1, 1, X_test_original_shape.shape[1])
# Now X_train_original_shape and X_test_original_shape have their original shapes
# Perform prediction on the original shape data
# y_pred = model.predict(X_test_reshaped)
y_pred = best_cnn_model.predict(X_test)
# Perform any necessary post-processing on y_pred if needed
# For example, if your model outputs probabilities, you might convert them to class labels using argmax:
y_pred_classes = np.argmax(y_pred, axis=1)
# Convert one-hot encoded y_test to class labels
y_test_classes = y_test
# Plot confusion matrix for test data
conf_matrix_test = confusion_matrix(y_test_classes, y_pred_classes)
# Plot confusion matrix
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix_test, annot=True, cmap='Blues', fmt='g', cbar=False)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Confusion Matrix - Test Data')
plt.show()
# Compute classification report
report = classification_report(y_test_classes, y_pred_classes)
print("Classification Report:\n", report)
print("Confusion Matrix for Hyperopt Model:")
print(confusion_matrix(y_test_classes, y_pred_classes))

1. Imports:
confusion_matrixfromsklearn.metricsfor calculating the confusion matrix.matplotlib.pyplot(plt) andseaborn(sns) for creating the confusion matrix visualization.classification_reportfromsklearn.metricsfor generating a classification report.
2. Reshaping Data (Commented Out):
- The commented section addresses potential reshaping issues. It’s important to ensure your test data (
X_test) has the correct shape expected by the model for prediction.
3. Prediction:
y_pred = model_cnn.predict(X_test)performs predictions on the test data using your trained model.
4. Post-processing Predictions:
y_pred_classes = np.argmax(y_pred, axis=2)assumes your model outputs probabilities for each class (neutral, long, short). This line converts the probabilities to class labels by usingargmax(finding the index of the maximum value) along axis 2.
5. Converting True Labels:
y_test_classes = y_testassumes youry_testdata already contains class labels (0, 1, 2) for the test set.
6. Confusion Matrix:
conf_matrix_test = confusion_matrix(y_test_classes, y_pred_classes)calculates the confusion matrix for the test data. It shows how many samples from each true class were predicted into each class by the model.
7. Visualization:
- The code creates a heatmap visualization of the confusion matrix using
seaborn. This allows you to visually inspect how well the model classified each class. Ideally, you want to see high values on the diagonal, indicating correct classifications.
8. Classification Report:
class_report = classification_report(y_test, y_pred_classes)generates a classification report for the test data. This report provides metrics like precision, recall, F1-score, and support for each class, offering a more detailed breakdown of the model's performance.- pen_spark
Backtest with Test and Whole Data:
df_ens_test = df.copy()
df_ens = df_ens_test[len(X_train):]
df_ens['best_cnn_model_scaled'] = np.argmax(best_cnn_model.predict(X_test), axis=1)
df_ens['bcns'] = df_ens['best_cnn_model_scaled'].shift(1).dropna().astype(int)
df_ens = df_ens.dropna()
df_ens['bcns']
# df_ens = df.copy()
# # df_ens = df_ens_test[len(X_train):]
# df_ens['best_cnn_model_scaled'] = np.argmax(best_cnn_model.predict(X), axis=1)
# df_ens['bcns'] = df_ens['best_cnn_model_scaled'].shift(-1).dropna().astype(int)
# df_ens = df_ens.dropna()
# df_ens['bcns']
df_ens = df_ens.reset_index(inplace=False)
df_ens['Date'] = pd.to_datetime(df_ens['Date'])
df_ens.set_index('Date', inplace=True)
def SIGNAL_2_6(df_ens):
return df_ens['bcns']
class MyCandlesStrat_2_6(Strategy):
def init(self):
super().init()
self.signal1_1 = self.I(SIGNAL_2_6, self.data)
def next(self):
super().next()
if self.signal1_1 == 1:
sl_pct = 0.055 # 10% stop-loss
tp_pct = 0.055 # 2.5% take-profit
sl_price = self.data.Close[-1] * (1 - sl_pct)
tp_price = self.data.Close[-1] * (1 + tp_pct)
self.buy(sl=sl_price, tp=tp_price)
elif self.signal1_1 == 2:
sl_pct = 0.055 # 10% stop-loss
tp_pct = 0.055 # 2.5% take-profit
sl_price = self.data.Close[-1] * (1 + sl_pct)
tp_price = self.data.Close[-1] * (1 - tp_pct)
self.sell(sl=sl_price, tp=tp_price)
bt_2_6 = Backtest(df_ens, MyCandlesStrat_2_6, cash=100000, commission=.001)
stat_2_6 = bt_2_6.run()
stat_2_6
Youtube Link Explanation of VishvaAlgo v4.x Features — Link
get entire code and profitable algos @ https://patreon.com/pppicasso
Data Preparation
df_ens_test = df.copy()
df_ens = df_ens_test[len(X_train):]
df_ens['best_cnn_model_scaled'] = np.argmax(best_cnn_model.predict(X_test), axis=1)
df_ens['bcns'] = df_ens['best_cnn_model_scaled'].shift(1).dropna().astype(int)
df_ens = df_ens.dropna()- df_ens_test = df.copy(): Creates a copy of the original dataframe
dfto ensure the original data is not altered. - df_ens = df_ens_test[len(X_train):]: Selects the portion of the dataframe corresponding to the test set by slicing off the length of the training data.
- df_ens[‘best_cnn_model_scaled’] = np.argmax(best_cnn_model.predict(X_test), axis=1): Uses the trained CNN model to predict class labels on the test set (
X_test). Thenp.argmaxfunction is used to get the class with the highest probability for each prediction. - df_ens[‘bcns’] = df_ens[‘best_cnn_model_scaled’].shift(1).dropna().astype(int): Shifts the predicted class labels by 1 position to avoid look-ahead bias (using future data to make predictions for the current step). Drops any resulting
NaNvalues and converts the series to integers. - df_ens = df_ens.dropna(): Ensures no
NaNvalues are left in the dataframe.
Indexing and Date Formatting
df_ens = df_ens.reset_index(inplace=False)
df_ens['Date'] = pd.to_datetime(df_ens['Date'])
df_ens.set_index('Date', inplace=True)- df_ens = df_ens.reset_index(inplace=False): Resets the index of the dataframe without modifying it in place.
- df_ens[‘Date’] = pd.to_datetime(df_ens[‘Date’]): Converts the ‘Date’ column to datetime format.
- df_ens.set_index(‘Date’, inplace=True): Sets the ‘Date’ column as the index of the dataframe.
Signal Function
def SIGNAL_2_6(df_ens):
return df_ens['bcns']- SIGNAL_2_6(df_ens): A function that returns the ‘bcns’ column, which contains the shifted class labels (signals).
Custom Trading Strategy
class MyCandlesStrat_2_6(Strategy):
def init(self):
super().init()
self.signal1_1 = self.I(SIGNAL_2_6, self.data)
def next(self):
super().next()
if self.signal1_1 == 1:
sl_pct = 0.055 # 5.5% stop-loss
tp_pct = 0.055 # 5.5% take-profit
sl_price = self.data.Close[-1] * (1 - sl_pct)
tp_price = self.data.Close[-1] * (1 + tp_pct)
self.buy(sl=sl_price, tp=tp_price)
elif self.signal1_1 == 2:
sl_pct = 0.055 # 5.5% stop-loss
tp_pct = 0.055 # 5.5% take-profit
sl_price = self.data.Close[-1] * (1 + sl_pct)
tp_price = self.data.Close[-1] * (1 - tp_pct)
self.sell(sl=sl_price, tp=tp_price)- class MyCandlesStrat_2_6(Strategy): Defines a custom trading strategy class inheriting from
Strategy. - def init(self): Initialization method. The
self.signal1_1attribute is set to the signal functionSIGNAL_2_6, which provides the trading signals. - def next(self): The core logic of the strategy executed at each step.
- if self.signal1_1 == 1: If the signal is 1, a long position is taken with a 5.5% stop-loss and take-profit.
- elif self.signal1_1 == 2: If the signal is 2, a short position is taken with a 5.5% stop-loss and take-profit.
Backtesting the Strategy
bt_2_6 = Backtest(df_ens, MyCandlesStrat_2_6, cash=100000, commission=.001)
stat_2_6 = bt_2_6.run()
stat_2_6- bt_2_6 = Backtest(df_ens, MyCandlesStrat_2_6, cash=100000, commission=.001): Initializes a backtest with the prepared dataframe
df_ens, the custom strategyMyCandlesStrat_2_6, an initial cash balance of 100,000 units, and a commission rate of 0.1%. - stat_2_6 = bt_2_6.run(): Runs the backtest.
- stat_2_6: Outputs the results and statistics of the backtest.
Advantages of 2D CNN Over 1D CNN
Capturing Complex Patterns:
- 2D CNN: Can capture spatial relationships and interactions between different features across time, which is essential for multivariate time series data.
- 1D CNN: Typically focuses on temporal patterns within a single feature or one-dimensional sequence.
Dimensionality Reduction:
- 2D CNN: Efficiently reduces dimensionality while preserving important features through pooling layers.
- 1D CNN: May require more layers or parameters to achieve similar results.
Feature Interactions:
- 2D CNN: Can learn complex interactions between different features, providing a richer representation of the data.
- 1D CNN: Limited to learning patterns in one dimension, which may not capture the full complexity of multivariate data.
By using a 2D CNN, this approach leverages its ability to capture intricate patterns and interactions in multivariate time series data, potentially leading to better performance in predicting trading signals.
from keras.models import save_model
best_cnn_model.save(f"./models/best_cnn_model_2d_15m_ETH_SL55_TP55_ShRa_{round(stat_2_6['Sharpe Ratio'],2)}_time_{time.strftime('%Y%m%d%H%M%S')}.keras")Explanation:
- Import:
save_modelfromkeras.modelsis used to save the model.
2. Filename Definition:
- The filename is constructed using an f-string (formatted string literal). It incorporates various details:
- Path:
./models/: This specifies the directory where you want to save the model. - Model Name:
transformer_model: Base name for the model. - Hyperparameters:
_55sl_55tp: Likely indicates the stop-loss (SL) and take-profit (TP) values used in your backtesting strategy. - Data Info:
_eth_15m: Possibly refers to the data being Ethereum (ETH) prices with a 15-minute time frame. - Date:
_may_13th: The date the model was trained (May 13th). - Performance Metric:
_ShRa_{round(stat_1['Sharpe Ratio'],2)}: Appends the Sharpe Ratio from the backtesting results (stat_1), rounded to two decimal places. - File Extension:
.keras: Standard extension for Keras models.
3. Saving the Model:
save_model(model_transformer, filename): This line saves your trainedmodel_transformerto the specified file with the constructed filename.
Key Points:
- This approach provides a clear and informative way to save our model, including details about its training parameters, data, and performance.
- You can modify the filename structure to include additional information relevant to your needs.
Let’s Backtest entire data with saved model:
from keras.models import load_model
# # Load the ensemble_predict function using joblib
best_model = load_model('./models/cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.68_time_20240527170917.keras')Intended Functionality:
- Import:
load_modelfromkeras.modelsis used to load a saved model.
2. Loading the Model:
best_model = load_model('./models/transformer_model_55sl_55tp_eth_15m_may_13th_ShRa_0.78.keras'): This line attempts to load a model saved with the filenametransformer_model_55sl_55tp_eth_15m_may_13th_ShRa_0.78.kerasfrom the directory./models/.
df_ens = df.copy()
# df_ens = df_ens_test[:len(X)]
y_pred = best_model.predict(X)
# Perform any necessary post-processing on y_pred if needed
# For example, if your model outputs probabilities, you might convert them to class labels using argmax:
# y_pred_classes = np.argmax(y_pred, axis=1)
# y_pred = np.argmax(y_pred, axis=1) # for lstm, tcn, cnn models
y_pred = np.argmax(y_pred, axis=2) # for transformers model
df_ens['best_model'] = y_pred
df_ens['bm'] = df_ens['best_model'].shift(1).dropna().astype(int)
df_ens['ema_22'] = ta.EMA(df_ens['Close'], timeperiod=22)
df_ens['ema_55'] = ta.EMA(df_ens['Close'], timeperiod=55)
df_ens['ema_108'] = ta.EMA(df_ens['Close'], timeperiod=108)
df_ens = df_ens.dropna()
df_ens['bm']
df_ens = df_ens.reset_index(inplace=False)
df_ens['Date'] = pd.to_datetime(df_ens['Date'])
df_ens.set_index('Date', inplace=True)
def SIGNAL_010(df_ens):
return df_ens['bm']
def SIGNAL_0122(df_ens):
return df_ens['ema_22']
def SIGNAL_0155(df_ens):
return df_ens['ema_55']
def SIGNAL_01108(df_ens):
return df_ens['ema_108']
class MyCandlesStrat_010(Strategy):
def init(self):
super().init()
self.signal1_1 = self.I(SIGNAL_010, self.data)
self.ema_1_22 = self.I(SIGNAL_0122, self.data)
self.ema_1_55 = self.I(SIGNAL_0155, self.data)
self.ema_1_108 = self.I(SIGNAL_01108, self.data)
def next(self):
super().next()
# if (self.signal1_1 == 1) and (self.data.Close > self.ema_1_22) and (self.ema_1_22 > self.ema_1_55) and (self.ema_1_55 > self.ema_1_108):
# sl_pct = 0.025 # 10% stop-loss
# tp_pct = 0.025 # 2.5% take-profit
# sl_price = self.data.Close[-1] * (1 - sl_pct)
# tp_price = self.data.Close[-1] * (1 + tp_pct)
# self.buy(sl=sl_price, tp=tp_price)
# elif (self.signal1_1 == 2) and (self.data.Close < self.ema_1_22) and (self.ema_1_22 < self.ema_1_55) and (self.ema_1_55 < self.ema_1_108):
# sl_pct = 0.025 # 10% stop-loss
# tp_pct = 0.025 # 2.5% take-profit
# sl_price = self.data.Close[-1] * (1 + sl_pct)
# tp_price = self.data.Close[-1] * (1 - tp_pct)
# self.sell(sl=sl_price, tp=tp_price)
# def next(self):
# super().next()
# if (self.signal1_1 == 1) and (self.ema_1_22 > self.ema_1_55) and (self.ema_1_55 > self.ema_1_108):
# sl_pct = 0.025 # 10% stop-loss
# tp_pct = 0.025 # 2.5% take-profit
# sl_price = self.data.Close[-1] * (1 - sl_pct)
# tp_price = self.data.Close[-1] * (1 + tp_pct)
# self.buy(sl=sl_price, tp=tp_price)
# elif (self.signal1_1 == 2) and (self.ema_1_22 < self.ema_1_55) and (self.ema_1_55 < self.ema_1_108):
# sl_pct = 0.025 # 10% stop-loss
# tp_pct = 0.025 # 2.5% take-profit
# sl_price = self.data.Close[-1] * (1 + sl_pct)
# tp_price = self.data.Close[-1] * (1 - tp_pct)
# self.sell(sl=sl_price, tp=tp_price)
if (self.signal1_1 == 1):
sl_pct = 0.035 # 10% stop-loss
tp_pct = 0.025 # 2.5% take-profit
sl_price = self.data.Close[-1] * (1 - sl_pct)
tp_price = self.data.Close[-1] * (1 + tp_pct)
self.buy(sl=sl_price, tp=tp_price)
elif (self.signal1_1 == 2):
sl_pct = 0.035 # 10% stop-loss
tp_pct = 0.025 # 2.5% take-profit
sl_price = self.data.Close[-1] * (1 + sl_pct)
tp_price = self.data.Close[-1] * (1 - tp_pct)
self.sell(sl=sl_price, tp=tp_price)
bt_010 = Backtest(df_ens, MyCandlesStrat_010, cash=100000, commission=.001)
stat_010 = bt_010.run()
stat_010
Youtube Link Explanation of VishvaAlgo v4.x Features — Link
get entire code and profitable algos @ https://patreon.com/pppicasso
This code builds upon your previous strategy by incorporating a Transformer model prediction ('best_model') along with Exponential Moving Averages (EMAs) to generate buy and sell signals for a backtesting strategy. Here's a breakdown:
1. Data Preparation:
df_ens = df.copy(): Creates a copy of the original DataFrame (df).y_pred = best_model.predict(X): Makes predictions on the entire DataFrame (X) using your loaded Transformer model (best_model).df_ens['best_model'] = y_pred: Adds a new column'best_model'to the DataFrame containing the model predictions.df_ens['bm'] = df_ens['best_model'].shift(1).dropna().astype(int): Similar to before, this creates a shifted signal column'bm'based on the predicted labels, but here it might include predictions for the entire DataFrame.df_ens['ema_22'] = ta.EMA(df_ens['Close'], timeperiod=22): Calculates the 22-period EMA for the 'Close' price and adds it as a new column'ema_22'.df_ens['ema_55'] = ta.EMA(df_ens['Close'], timeperiod=55): Similar to above, calculates the 55-period EMA and adds it as'ema_55'.df_ens['ema_108'] = ta.EMA(df_ens['Close'], timeperiod=108): Calculates the 108-period EMA and adds it as'ema_108'.df_ens = df_ens.dropna(): Removes rows with missing values (likely the first row due to shifting).
2. Signal Functions (Outside the Code Block):
- These functions (
SIGNAL_010,SIGNAL_0122, etc.) simply return the corresponding columns from the DataFrame ('bm','ema_22', etc.) used for generating the signals.
3. Backtesting Strategy Class (MyCandlesStrat_010):
- Inherits from
Strategy. def init(self): Initializes indicators for the Transformer model predictions (self.signal1_1) and EMAs (self.ema_1_22, etc.).
4. Backtesting Logic (in next function):
- The commented-out section shows a more complex logic considering the relationship between the Transformer predictions and the EMAs for buy/sell decisions.
- The current active section uses a simpler approach:
- If
self.signal1_1(Transformer prediction) is 1 (long): - Buy with stop-loss (SL) at 3.5% below current close and take-profit (TP) at 2.5% above.
- If
self.signal1_1is 2 (short): - Sell with SL at 3.5% above current close and TP at 2.5% below.
5. Backtesting and Results:
bt_010 = Backtest(df_ens, MyCandlesStrat_010, cash=100000, commission=.001): Creates a backtest object using the DataFrame, strategy class, and other parameters.stat_010 = bt_010.run(): Runs the backtest and stores the results instat_010.stat_010: This variable likely contains the backtesting statistics you can analyze.
Key Points:
- This strategy combines predictions from our Transformer model with technical indicators (EMAs) for generating signals.
- You can experiment with different conditions in the
nextfunction to create more sophisticated trading strategies. - Remember that backtesting results may not guarantee future performance, and proper risk management is crucial for real-world trading
Conclusion for 2D CNN Model:
The given code sets up a 2D CNN model with hyperparameter tuning using Keras Tuner. The model is designed to handle multi-class classification for time series data of cryptocurrencies. By leveraging 2D CNNs, the model can capture intricate patterns across both time and features, potentially leading to more accurate and robust predictions compared to 1D CNNs. The use of hyperparameter tuning ensures that the model is optimized for the given task, further enhancing its performance.
Applying 2D CNN Model for Other Assets and Short List the Best:
From here on we will explain about how to use the same trained model to short list best assets after doing certain backtest on all the assets after downloading the data from tradingview for backtest
Importing Necessary packages and setting up Model & Exchange APi with CCXT
import time
import logging
import io
import contextlib
import glob
import ccxt
from datetime import datetime, timedelta, timezone
import keras
from keras.models import save_model, load_model
import numpy as np
import pandas as pd
import talib as ta
from sklearn.preprocessing import MinMaxScaler
import warnings
from threading import Thread, Event
import decimal
import joblib
from tcn import TCN
# from pandas.core.computation import PerformanceWarning
# Suppress PerformanceWarning
warnings.filterwarnings("ignore")
# NOTE: Train your own model from the other notebook I have shared and use the most successful trained model here.
# model_file_path = './model_lstm_1tp_1sl_2p5SlTp_April_5th_ShRa_1_49_15m.hdf5'
model_file_path = './models/transformer_model_55sl_55tp_eth_15m_may_13th_ShRa_0.78.keras'
model_name = model_file_path.split('/')[-1]
##################################### TO Load A Model #######################################
# NOTE: for LSTM based neural network model you can directly load_model with model_file_path as given below
# Load your pre-trained model, keras trained model will only take load_model from keras.models and not from joblib
model = load_model(model_file_path)
# # or
# model = tf.keras.models.load_model(model_file_path)
# NOTE: for TCN based neural network model, you need to add custom_objects while loading the model, it is given below
# # Define a dictionary to specify custom objects
# custom_objects = {'TCN': TCN}
# model = load_model(model_file_path, custom_objects = custom_objects)
##########################################################################################
########################## Adding the exchange information ##############################
exchange = ccxt.binanceusdm(
{
'enableRateLimit': True, # required by the Manual
# Add any other authentication parameters if needed
'rateLimit': 250, 'verbose': True
}
)
# NOTE: I used https://testnet.binancefuture.com/en/futures/BTCUSDT for testnet API (this has very bad liquidity issue for various assets and many other issues but can be used for purely testiug purpose)
# kraken testnet creds pubkey - K9dS2SK8JURMl9F300lguUhOS/ao3HM+tfRMgJGed+JhDfpJhvsC/y privatekey - /J/03PPyPwsrPsKZYtLqOQNPLKZJattT6i15Bpg14/6ALokHHY/MBb1p6tYKyFgkKXIJIOMbBsFRfL3aBZUvQ1
# api_key = '8f7080f8821b58a53f5c49f00cbff7fdccca9c9154ea'
# secret_key = '1e58391a46a7dbb098aa5121d3e69e3a6660ba8c38f'
# exchange.apiKey = api_key
# exchange.secret = secret_key
# exchange.set_sandbox_mode(True)
# NOTE: if u want to go live, un commenb below 5 lines and comment 5 lines above and change to your own api_key and secret_key (below one ius a dummy and also make sure to give "futres" permission while creating your api in the exchange)
api_key = 'CxUdC80c3Y5Nf1iRJMZJelOCfFJWISbQsasCb4Zdskx7MM8uCl'
secret_key = 'p4XwsZwmmNswzDHzE5TSUOgXT5tASArfSOfYrBMtezlCpDGtz'
exchange.apiKey = api_key
exchange.secret = secret_key
exchange.set_sandbox_mode(False)
#######################################################################################
# exchange.set_sandbox_mode(True)
exchange.has
# exchange.fetchBalance()["info"]["assets"]
exchange.options = {'defaultType': 'future', # or 'margin' or 'spot'
'timeDifference': 0, # Set an appropriate initial value for time difference
'adjustForTimeDifference': True,
'newOrderRespType': 'FULL',
'defaultTimeInForce': 'GTC'}The provided code snippet demonstrates how to load our trained model and connect to a cryptocurrency exchange (Binance) for potential shortlisting of assets based on backtesting. Here’s a breakdown:
Imports:
- Standard libraries for time, logging, data manipulation (pandas, numpy), machine learning (Keras, scikit-learn), technical indicators (talib), threading, and others.
Model Loading:
- Comments explain the difference in loading a model based on its type:
- LSTM Model: Uses
load_modelfromkeras.modelsdirectly (as shown in your code). - TCN Model: Requires specifying custom objects (
custom_objects={'TCN': TCN}) during loading.
Exchange Connection:
- Creates a
ccxt.binanceusdmobject (exchange) to interact with the Binance exchange. - Sets API credentials and enables rate limiting for responsible API usage.
- Comments mention testnet and live API usage options.
Important Notes:
- Replace API Keys: Replace the dummy
api_keyandsecret_keywith your actual Binance API credentials (if going live). Ensure your API has "futures" permission. - Backtesting Not Shown: This code focuses on model loading and exchange connection. The actual backtesting loop and asset shortlisting logic are not included.
Next Steps:
- Backtesting Loop: You’ll need to implement a loop to iterate through your desired assets:
- Download historical data from the exchange (using
exchange.fetch_ohlcv) for each asset. - Preprocess the data (scaling, feature engineering).
- Make predictions using your loaded model (
model.predict). - Apply your backtesting strategy (similar to previous examples) incorporating predictions and potentially technical indicators.
- Store backtesting results for each asset.
- Shortlisting: Analyze the stored backtesting results and apply filters/sorting based on your chosen metrics to shortlist the best-performing assets.
- Risk Management: Remember, backtesting is for evaluation, not a guarantee of future success. Implement proper risk management strategies before using these shortlisted assets in real trading.
from sklearn.preprocessing import MinMaxScaler
from backtesting import Strategy, Backtest
import os
import json
import pandas as pd
import talib as ta
import numpy as np
from concurrent.futures import ThreadPoolExecutor
import threading
import time
import ccxt
from keras.models import save_model, load_model
import warnings
import decimal
import joblib
import nest_asyncio
# from pandas.core.computation import PerformanceWarning
# Suppress PerformanceWarning
warnings.filterwarnings("ignore")
# Load your pre-trained model
# model = load_model('best_model_tcn_1sl_1tp_2p5SlTp_success.pkl')
# Define the custom_assets dictionary outside the loop
custom_assets = {}
# Function to load custom_assets from a text file
def load_custom_assets():
if os.path.exists('custom_assets.txt'):
try:
with open('custom_assets.txt', 'r') as txt_file:
return json.loads(txt_file.read())
except json.JSONDecodeError as e:
print(f"Error decoding JSON in custom_assets.txt: {e}")
return {}
else:
print("custom_assets.txt file not found. Initializing an empty dictionary.")
custom_assets = {}
save_custom_assets(custom_assets)
return custom_assets
# Define a threading lock
file_lock = threading.Lock()
# Function to save custom_assets to a text file
def save_custom_assets(custom_assets):
with file_lock:
with open('custom_assets.txt', 'w') as txt_file:
json.dump(custom_assets, txt_file, indent=4)The provided code focuses on managing custom assets and preparing for multi-threaded backtesting. Here’s a breakdown:
Imports:
- Includes libraries for data manipulation (pandas, numpy), technical indicators (talib), backtesting framework (
backtesting), threading, and others.
Custom Assets Management:
custom_assets dictionary:
- Stores custom assets for backtesting (likely symbols or names).
load_custom_assets function:
- Checks for a file named
custom_assets.txt. - If the file exists, attempts to load the dictionary from the JSON content. Handles potential JSON decoding errors.
- If the file doesn’t exist, initializes an empty dictionary, saves it, and returns it.
save_custom_assets function:
- Uses a threading lock (
file_lock) to ensure safe access to the file during potential concurrent writes. - Saves the
custom_assetsdictionary as JSON to thecustom_assets.txtfile.
Next Steps:
- Backtesting Function: You’ll likely define a function for the backtesting logic. This function would:
- Take an asset symbol as input.
- Download historical data for the asset.
- Preprocess the data (scaling, feature engineering).
- Make predictions using your loaded model.
- Apply your backtesting strategy (similar to previous examples) incorporating predictions and potentially technical indicators.
- Calculate and store backtesting results (Sharpe Ratio, drawdown, etc.) for the asset.
2. Multithreaded Backtesting:
- You can utilize the
ThreadPoolExecutorand threading capabilities to download and backtest multiple assets simultaneously. This can significantly improve efficiency compared to a sequential approach. - The
custom_assetsdictionary and its management functions will be crucial for providing asset symbols to the backtesting function within the thread pool.
Additional Notes:
- Remember to replace
'best_model_tcn_1sl_1tp_2p5SlTp_success.pkl'with the actual path to your trained model file. - Consider error handling and logging mechanisms for potential issues during data download, backtesting calculations, or thread management.
#NOTE: Fetching from binance Futures perpetual USDT assets , if error 4xx accours, it means, there is some restriction from your government or VPN server is connected to restrcited area for binance to work. You can use assets from the collection given by me in next cell
import requests
def get_binance_futures_assets():
url = "https://fapi.binance.com/fapi/v1/exchangeInfo"
try:
response = requests.get(url)
response.raise_for_status() # Raise an exception for 4xx and 5xx status codes
data = response.json()
assets = [asset['symbol'] for asset in data['symbols'] if asset['contractType'] == 'PERPETUAL' and asset['quoteAsset'] == 'USDT']
return assets
except requests.exceptions.RequestException as e:
print("Failed to fetch Binance futures assets:", e)
return []
# Get all Binance futures USDT perpetual assets
futures_assets = get_binance_futures_assets()
print("Binance Futures USDT Perpetual Assets:")
print(futures_assets, len(futures_assets))output:
'BTCUSDT.P', 'ETHUSDT.P', 'BCHUSDT.P', 'XRPUSDT.P', 'EOSUSDT.P', 'LTCUSDT.P', 'TRXUSDT.P', 'ETCUSDT.P',
'LINKUSDT.P', 'XLMUSDT.P', 'ADAUSDT.P', 'XMRUSDT.P', 'DASHUSDT.P', 'ZECUSDT.P', 'XTZUSDT.P', 'BNBUSDT.P',
'ATOMUSDT.P', 'ONTUSDT.P', 'IOTAUSDT.P', 'BATUSDT.P', 'VETUSDT.P', 'NEOUSDT.P', 'QTUMUSDT.P', 'IOSTUSDT.P',
'THETAUSDT.P', 'ALGOUSDT.P', 'ZILUSDT.P', 'KNCUSDT.P', 'ZRXUSDT.P', 'COMPUSDT.P', 'OMGUSDT.P', 'DOGEUSDT.P',
'SXPUSDT.P', 'KAVAUSDT.P', 'BANDUSDT.P', 'RLCUSDT.P', 'WAVESUSDT.P', 'MKRUSDT.P', 'SNXUSDT.P', 'DOTUSDT.P',
'DEFIUSDT.P', 'YFIUSDT.P', 'BALUSDT.P', 'CRVUSDT.P', 'TRBUSDT.P', 'RUNEUSDT.P', 'SUSHIUSDT.P', 'SRMUSDT.P',
'EGLDUSDT.P', 'SOLUSDT.P', 'ICXUSDT.P', 'STORJUSDT.P', 'BLZUSDT.P', 'UNIUSDT.P', 'AVAXUSDT.P', 'FTMUSDT.P',
'HNTUSDT.P', 'ENJUSDT.P', 'FLMUSDT.P', 'TOMOUSDT.P', 'RENUSDT.P', 'KSMUSDT.P', 'NEARUSDT.P', 'AAVEUSDT.P',
'FILUSDT.P', 'RSRUSDT.P', 'LRCUSDT.P', 'MATICUSDT.P', 'OCEANUSDT.P', 'CVCUSDT.P', 'BELUSDT.P', 'CTKUSDT.P',
'AXSUSDT.P', 'ALPHAUSDT.P', 'ZENUSDT.P', 'SKLUSDT.P', 'GRTUSDT.P', '1INCHUSDT.P', 'CHZUSDT.P', 'SANDUSDT.P',
'ANKRUSDT.P', 'BTSUSDT.P', 'LITUSDT.P', 'UNFIUSDT.P', 'REEFUSDT.P', 'RVNUSDT.P', 'SFPUSDT.P', 'XEMUSDT.P',
'COTIUSDT.P', 'CHRUSDT.P', 'MANAUSDT.P', 'ALICEUSDT.P', 'HBARUSDT.P', 'ONEUSDT.P', 'LINAUSDT.P', 'STMXUSDT.P',
'DENTUSDT.P', 'CELRUSDT.P', 'HOTUSDT.P', 'MTLUSDT.P', 'OGNUSDT.P', 'NKNUSDT.P', 'SCUSDT.P', 'DGBUSDT.P',
'1000SHIBUSDT.P', 'BAKEUSDT.P', 'GTCUSDT.P', 'BTCDOMUSDT.P', 'IOTXUSDT.P', 'AUDIOUSDT.P', 'RAYUSDT.P', 'C98USDT.P',
'MASKUSDT.P', 'ATAUSDT.P', 'DYDXUSDT.P', '1000XECUSDT.P', 'GALAUSDT.P', 'CELOUSDT.P', 'ARUSDT.P', 'KLAYUSDT.P',
'ARPAUSDT.P', 'CTSIUSDT.P', 'LPTUSDT.P', 'ENSUSDT.P', 'PEOPLEUSDT.P', 'ANTUSDT.P', 'ROSEUSDT.P', 'DUSKUSDT.P',
'FLOWUSDT.P', 'IMXUSDT.P', 'API3USDT.P', 'GMTUSDT.P', 'APEUSDT.P', 'WOOUSDT.P', 'FTTUSDT.P', 'JASMYUSDT.P', 'DARUSDT.P',
'GALUSDT.P', 'OPUSDT.P', 'INJUSDT.P', 'STGUSDT.P', 'FOOTBALLUSDT.P', 'SPELLUSDT.P', '1000LUNCUSDT.P',
'LUNA2USDT.P', 'LDOUSDT.P', 'CVXUSDT.P', 'ICPUSDT.P', 'APTUSDT.P', 'QNTUSDT.P', 'BLUEBIRDUSDT.P', 'FETUSDT.P',
'FXSUSDT.P', 'HOOKUSDT.P', 'MAGICUSDT.P', 'TUSDT.P', 'RNDRUSDT.P', 'HIGHUSDT.P', 'MINAUSDT.P', 'ASTRUSDT.P',
'AGIXUSDT.P', 'PHBUSDT.P', 'GMXUSDT.P', 'CFXUSDT.P', 'STXUSDT.P', 'COCOSUSDT.P', 'BNXUSDT.P', 'ACHUSDT.P',
'SSVUSDT.P', 'CKBUSDT.P', 'PERPUSDT.P', 'TRUUSDT.P', 'LQTYUSDT.P', 'USDCUSDT.P', 'IDUSDT.P', 'ARBUSDT.P',
'JOEUSDT.P', 'TLMUSDT.P', 'AMBUSDT.P', 'LEVERUSDT.P', 'RDNTUSDT.P', 'HFTUSDT.P', 'XVSUSDT.P', 'BLURUSDT.P',
'EDUUSDT.P', 'IDEXUSDT.P', 'SUIUSDT.P', '1000PEPEUSDT.P', '1000FLOKIUSDT.P', 'UMAUSDT.P', 'RADUSDT.P',
'KEYUSDT.P', 'COMBOUSDT.P', 'NMRUSDT.P', 'MAVUSDT.P', 'MDTUSDT.P', 'XVGUSDT.P', 'WLDUSDT.P', 'PENDLEUSDT.P',
'ARKMUSDT.P', 'AGLDUSDT.P', 'YGGUSDT.P', 'DODOXUSDT.P', 'BNTUSDT.P', 'OXTUSDT.P', 'SEIUSDT.P', 'CYBERUSDT.P',
'HIFIUSDT.P', 'ARKUSDT.P', 'FRONTUSDT.P', 'GLMRUSDT.P', 'BICOUSDT.P', 'STRAXUSDT.P', 'LOOMUSDT.P', 'BIGTIMEUSDT.P',
'BONDUSDT.P', 'ORBSUSDT.P', 'STPTUSDT.P', 'WAXPUSDT.P', 'BSVUSDT.P', 'RIFUSDT.P', 'POLYXUSDT.P', 'GASUSDT.P',
'POWRUSDT.P', 'SLPUSDT.P', 'TIAUSDT.P', 'SNTUSDT.P', 'CAKEUSDT.P', 'MEMEUSDT.P', 'TWTUSDT.P', 'TOKENUSDT.P',
'ORDIUSDT.P', 'STEEMUSDT.P', 'BADGERUSDT.P', 'ILVUSDT.P', 'NTRNUSDT.P', 'MBLUSDT.P', 'KASUSDT.P', 'BEAMXUSDT.P',
'1000BONKUSDT.P', 'PYTHUSDT.P', 'SUPERUSDT.P', 'USTCUSDT.P', 'ONGUSDT.P', 'ETHWUSDT.P', 'JTOUSDT.P', '1000SATSUSDT.P',
'AUCTIONUSDT.P', '1000RATSUSDT.P', 'ACEUSDT.P', 'MOVRUSDT.P', 'NFPUSDT.P', 'AIUSDT.P', 'XAIUSDT.P',
'WIFUSDT.P', 'MANTAUSDT.P', 'ONDOUSDT.P', 'LSKUSDT.P', 'ALTUSDT.P', 'JUPUSDT.P', 'ZETAUSDT.P', 'RONINUSDT.P',
'DYMUSDT.P', 'OMUSDT.P', 'PIXELUSDT.P', 'STRKUSDT.P', 'MAVIAUSDT.P', 'GLMUSDT.P', 'PORTALUSDT.P', 'TONUSDT.P',
'AXLUSDT.P', 'MYROUSDT.P', 'METISUSDT.P', 'AEVOUSDT.P', 'VANRYUSDT.P', 'BOMEUSDT.P', 'ETHFIUSDT.P', 'ENAUSDT.P',
'WUSDT.P', 'TNSRUSDT.P', 'SAGAUSDT.P', 'TAOUSDT.P', 'OMNIUSDT.P', 'REZUSDT.P'This code snippet retrieves a list of perpetual USDT contracts available on Binance Futures using the official Binance API. Here’s a breakdown:
Function:
get_binance_futures_assets function:
- Defines the API endpoint URL for retrieving exchange information.
- Uses a try-except block to handle potential errors during the request.
Within the try block:
- Makes a GET request to the Binance API endpoint.
- Raises an exception for status codes in the 4xx (client errors) or 5xx (server errors) range to indicate failures.
- Parses the JSON response from the successful request.
Extracts symbols from the response data:
- Iterates through the
'symbols'list in the JSON data.
Filters for assets with these criteria:
'contractType'is 'PERPETUAL' (indicates perpetual contracts).'quoteAsset'is 'USDT' (indicates USDT-quoted contracts).- Creates a list of asset symbols meeting the criteria and returns it.
- The except block catches potential request exceptions and prints an error message. It also returns an empty list in case of failures.
Printing Results:
- Calls the
get_binance_futures_assetsfunction to retrieve the asset list. - Prints a message indicating the retrieved assets and their count.
Additional Notes:
- This approach leverages the official Binance API, which might be subject to rate limits or changes in the future. Consider implementing appropriate error handling and retry mechanisms.
- The code assumes a successful API call. You might want to add checks for specific error codes (e.g., 429 for “Too Many Requests”) and handle them gracefully (e.g., retrying after a delay).
# !pip install --upgrade --no-cache-dir git+https://github.com/rongardF/tvdatafeed.git
import os
import json
import asyncio
from datetime import datetime, timedelta
import pandas as pd
from tvDatafeed import TvDatafeed, Interval
# Initialize TvDatafeed object
# username = 'YourTradingViewUsername'
# password = 'YourTradingViewPassword'
# tv = TvDatafeed(username, password)
tv = TvDatafeed()
timeframe = '15m'
interval = None
if timeframe == '1m':
interval = Interval.in_1_minute
elif timeframe == '3m':
interval = Interval.in_3_minute
elif timeframe == '5m':
interval = Interval.in_5_minute
elif timeframe == '15m':
interval = Interval.in_15_minute
elif timeframe == '30m':
interval = Interval.in_30_minute
elif timeframe == '45m':
interval = Interval.in_45_minute
elif timeframe == '1h':
interval = Interval.in_1_hour
elif timeframe == '2h':
interval = Interval.in_2_hour
elif timeframe == '4h':
interval = Interval.in_4_hour
elif timeframe == '1d':
interval = Interval.in_daily
elif timeframe == '1w':
interval = Interval.in_weekly
elif timeframe == '1M':
interval = Interval.in_monthly
# NOTE: List of symbols around 126 mentioned here. You can change to your own set of lists if you know the tradingview code for the symbol you want to download.
data = [
'BTCUSDT.P', 'ETHUSDT.P', 'BCHUSDT.P', 'XRPUSDT.P', 'EOSUSDT.P', 'LTCUSDT.P', 'TRXUSDT.P', 'ETCUSDT.P',
'LINKUSDT.P', 'XLMUSDT.P', 'ADAUSDT.P', 'XMRUSDT.P', 'DASHUSDT.P', 'ZECUSDT.P', 'XTZUSDT.P', 'BNBUSDT.P',
'ATOMUSDT.P', 'ONTUSDT.P', 'IOTAUSDT.P', 'BATUSDT.P', 'VETUSDT.P', 'NEOUSDT.P', 'QTUMUSDT.P', 'IOSTUSDT.P',
'THETAUSDT.P', 'ALGOUSDT.P', 'ZILUSDT.P', 'KNCUSDT.P', 'ZRXUSDT.P', 'COMPUSDT.P', 'OMGUSDT.P', 'DOGEUSDT.P',
'SXPUSDT.P', 'KAVAUSDT.P', 'BANDUSDT.P', 'RLCUSDT.P', 'WAVESUSDT.P', 'MKRUSDT.P', 'SNXUSDT.P', 'DOTUSDT.P',
'DEFIUSDT.P', 'YFIUSDT.P', 'BALUSDT.P', 'CRVUSDT.P', 'TRBUSDT.P', 'RUNEUSDT.P', 'SUSHIUSDT.P', 'SRMUSDT.P',
'EGLDUSDT.P', 'SOLUSDT.P', 'ICXUSDT.P', 'STORJUSDT.P', 'BLZUSDT.P', 'UNIUSDT.P', 'AVAXUSDT.P', 'FTMUSDT.P',
'HNTUSDT.P', 'ENJUSDT.P', 'FLMUSDT.P', 'TOMOUSDT.P', 'RENUSDT.P', 'KSMUSDT.P', 'NEARUSDT.P', 'AAVEUSDT.P',
'FILUSDT.P', 'RSRUSDT.P', 'LRCUSDT.P', 'MATICUSDT.P', 'OCEANUSDT.P', 'CVCUSDT.P', 'BELUSDT.P', 'CTKUSDT.P',
'AXSUSDT.P', 'ALPHAUSDT.P', 'ZENUSDT.P', 'SKLUSDT.P', 'GRTUSDT.P', '1INCHUSDT.P', 'CHZUSDT.P', 'SANDUSDT.P',
'ANKRUSDT.P', 'BTSUSDT.P', 'LITUSDT.P', 'UNFIUSDT.P', 'REEFUSDT.P', 'RVNUSDT.P', 'SFPUSDT.P', 'XEMUSDT.P',
'COTIUSDT.P', 'CHRUSDT.P', 'MANAUSDT.P', 'ALICEUSDT.P', 'HBARUSDT.P', 'ONEUSDT.P', 'LINAUSDT.P', 'STMXUSDT.P',
'DENTUSDT.P', 'CELRUSDT.P', 'HOTUSDT.P', 'MTLUSDT.P', 'OGNUSDT.P', 'NKNUSDT.P', 'SCUSDT.P', 'DGBUSDT.P',
'1000SHIBUSDT.P', 'BAKEUSDT.P', 'GTCUSDT.P', 'BTCDOMUSDT.P', 'IOTXUSDT.P', 'AUDIOUSDT.P', 'RAYUSDT.P', 'C98USDT.P',
'MASKUSDT.P', 'ATAUSDT.P', 'DYDXUSDT.P', '1000XECUSDT.P', 'GALAUSDT.P', 'CELOUSDT.P', 'ARUSDT.P', 'KLAYUSDT.P',
'ARPAUSDT.P', 'CTSIUSDT.P', 'LPTUSDT.P', 'ENSUSDT.P', 'PEOPLEUSDT.P', 'ANTUSDT.P', 'ROSEUSDT.P', 'DUSKUSDT.P',
'FLOWUSDT.P', 'IMXUSDT.P', 'API3USDT.P', 'GMTUSDT.P', 'APEUSDT.P', 'WOOUSDT.P', 'FTTUSDT.P', 'JASMYUSDT.P', 'DARUSDT.P',
'GALUSDT.P', 'OPUSDT.P', 'INJUSDT.P', 'STGUSDT.P', 'FOOTBALLUSDT.P', 'SPELLUSDT.P', '1000LUNCUSDT.P',
'LUNA2USDT.P', 'LDOUSDT.P', 'CVXUSDT.P', 'ICPUSDT.P', 'APTUSDT.P', 'QNTUSDT.P', 'BLUEBIRDUSDT.P', 'FETUSDT.P',
'FXSUSDT.P', 'HOOKUSDT.P', 'MAGICUSDT.P', 'TUSDT.P', 'RNDRUSDT.P', 'HIGHUSDT.P', 'MINAUSDT.P', 'ASTRUSDT.P',
'AGIXUSDT.P', 'PHBUSDT.P', 'GMXUSDT.P', 'CFXUSDT.P', 'STXUSDT.P', 'COCOSUSDT.P', 'BNXUSDT.P', 'ACHUSDT.P',
'SSVUSDT.P', 'CKBUSDT.P', 'PERPUSDT.P', 'TRUUSDT.P', 'LQTYUSDT.P', 'USDCUSDT.P', 'IDUSDT.P', 'ARBUSDT.P',
'JOEUSDT.P', 'TLMUSDT.P', 'AMBUSDT.P', 'LEVERUSDT.P', 'RDNTUSDT.P', 'HFTUSDT.P', 'XVSUSDT.P', 'BLURUSDT.P',
'EDUUSDT.P', 'IDEXUSDT.P', 'SUIUSDT.P', '1000PEPEUSDT.P', '1000FLOKIUSDT.P', 'UMAUSDT.P', 'RADUSDT.P',
'KEYUSDT.P', 'COMBOUSDT.P', 'NMRUSDT.P', 'MAVUSDT.P', 'MDTUSDT.P', 'XVGUSDT.P', 'WLDUSDT.P', 'PENDLEUSDT.P',
'ARKMUSDT.P', 'AGLDUSDT.P', 'YGGUSDT.P', 'DODOXUSDT.P', 'BNTUSDT.P', 'OXTUSDT.P', 'SEIUSDT.P', 'CYBERUSDT.P',
'HIFIUSDT.P', 'ARKUSDT.P', 'FRONTUSDT.P', 'GLMRUSDT.P', 'BICOUSDT.P', 'STRAXUSDT.P', 'LOOMUSDT.P', 'BIGTIMEUSDT.P',
'BONDUSDT.P', 'ORBSUSDT.P', 'STPTUSDT.P', 'WAXPUSDT.P', 'BSVUSDT.P', 'RIFUSDT.P', 'POLYXUSDT.P', 'GASUSDT.P',
'POWRUSDT.P', 'SLPUSDT.P', 'TIAUSDT.P', 'SNTUSDT.P', 'CAKEUSDT.P', 'MEMEUSDT.P', 'TWTUSDT.P', 'TOKENUSDT.P',
'ORDIUSDT.P', 'STEEMUSDT.P', 'BADGERUSDT.P', 'ILVUSDT.P', 'NTRNUSDT.P', 'MBLUSDT.P', 'KASUSDT.P', 'BEAMXUSDT.P',
'1000BONKUSDT.P', 'PYTHUSDT.P', 'SUPERUSDT.P', 'USTCUSDT.P', 'ONGUSDT.P', 'ETHWUSDT.P', 'JTOUSDT.P', '1000SATSUSDT.P',
'AUCTIONUSDT.P', '1000RATSUSDT.P', 'ACEUSDT.P', 'MOVRUSDT.P', 'NFPUSDT.P', 'AIUSDT.P', 'XAIUSDT.P',
'WIFUSDT.P', 'MANTAUSDT.P', 'ONDOUSDT.P', 'LSKUSDT.P', 'ALTUSDT.P', 'JUPUSDT.P', 'ZETAUSDT.P', 'RONINUSDT.P',
'DYMUSDT.P', 'OMUSDT.P', 'PIXELUSDT.P', 'STRKUSDT.P', 'MAVIAUSDT.P', 'GLMUSDT.P', 'PORTALUSDT.P', 'TONUSDT.P',
'AXLUSDT.P', 'MYROUSDT.P', 'METISUSDT.P', 'AEVOUSDT.P', 'VANRYUSDT.P', 'BOMEUSDT.P', 'ETHFIUSDT.P', 'ENAUSDT.P',
'WUSDT.P', 'TNSRUSDT.P', 'SAGAUSDT.P', 'TAOUSDT.P', 'OMNIUSDT.P', 'REZUSDT.P'
]
nest_asyncio.apply()
# Define data download function
async def download_data(symbol):
try:
data = tv.get_hist(symbol=symbol, exchange='BINANCE', interval=interval, n_bars=20000, extended_session=True)
if not data.empty:
# Convert Date objects to strings
# data['Date'] = data.index.date.astype(str)
# data['Time'] = data.index.time.astype(str)
data['date'] = data.index.astype(str) # Add a new column for timestamps
folder_name = f"tradingview_crypto_assets_{timeframe}"
os.makedirs(folder_name, exist_ok=True)
# Replace "USDT.P" with "/USDT:USDT" in the file name
symbol_file_name = symbol.replace("USDT.P", "") + ".json"
file_name = os.path.join(folder_name, symbol_file_name)
# Convert DataFrame to dictionary
data_dict = data.to_dict(orient='records')
with open(file_name, "w") as file:
# Serialize dictionary to JSON
json.dump(data_dict, file)
print(f"Data for {symbol} downloaded and saved successfully.")
else:
print(f"No data available for {symbol}.")
except Exception as e:
print(f"Error occurred while downloading data for {symbol}: {e}")
# Define main function to run async download tasks
async def main():
tasks = [download_data(symbol) for symbol in data]
await asyncio.gather(*tasks)
# Run the main function
asyncio.run(main())This code snippet demonstrates how to download historical cryptocurrency data from TradingView for multiple assets using the tvDatafeed library. Here's a breakdown:
Imports:
- Includes libraries for asynchronous programming (
asyncio), working with dates (datetime), data manipulation (pandas), and file handling (os,json). - Imports the
TvDatafeedclass fromtvDatafeedfor interacting with TradingView.
TvDatafeed Object:
- Initializes a
TvDatafeedobject (tv) without username and password (assuming a free account). Paid accounts might require credentials.
Timeframe and Interval:
- Sets the desired timeframe (
timeframe) for data download (e.g., "15m" for 15-minute intervals). - Maps the
timeframeto the correspondingIntervalenumeration value using a series ofifstatements.
Symbols List:
- Defines a long list of symbols (
data) representing cryptocurrencies on Binance Futures with perpetual USDT contracts (identified by ".P" suffix).
Asynchronous Programming Setup:
- Initializes
nest_asyncio.apply()to enable the use of asynchronous functions within a non-asynchronous context.
Download Function:
- Defines an asynchronous function
download_data(symbol)that takes a symbol as input.
Attempts to download historical data for the symbol using tv.get_hist:
- Specifies the symbol, exchange (“BINANCE”), interval, number of bars (20000), and extended session (to potentially capture pre-market/after-market data).
- Checks if downloaded data (
data) is not empty.
If data is available:
- Converts the index (timestamps) to strings in a new column named “date”.
- Creates a folder named
tradingview_crypto_assets_{timeframe}to store the downloaded data (creates it if it doesn't exist). - Constructs the filename by replacing “.P” with “/USDT:USDT” in the symbol and appending “.json”.
- Converts the DataFrame to a dictionary using
to_dict(orient='records'). - Saves the dictionary as JSON to the constructed filename.
- Prints a success message.
If no data is available:
- Prints a message indicating no data for the symbol.
- Catches any exceptions (
Exception) during download and prints an error message with the exception details.
Main Function:
- Defines an asynchronous function
mainthat: - Creates a list of asynchronous tasks (
tasks) using list comprehension. Each task callsdownload_datafor a symbol from thedatalist. - Uses
asyncio.gather(*tasks)to run all download tasks concurrently.
Running the Download:
- Uses
asyncio.run(main())to execute the asynchronous tasks within the main function.
Important Notes:
- This code retrieves data for a large number of symbols. Downloading a significant amount of data might exceed free account limitations or take a long time. Consider rate limits and adjust accordingly.
- The code assumes a specific symbol format with the “.P” suffix. You might need to modify it for different symbol formats.
- Error handling can be improved by implementing specific checks for different exception types (e.g., network errors, API errors).
Hyperoptimization of Multiple Assets for Specific ML/DL Model:
from pandas import Timestamp
# Define a function to process each JSON file
def process_json(file_path):
# try:
with open(file_path, "r") as f:
data = json.load(f)
df = pd.DataFrame(data)
df.rename(columns={'date': "Date", 'open': "Open", 'high': "High", 'low': "Low", 'close': "Adj Close", 'volume': "Volume"}, inplace=True)
df["Date"] = pd.to_datetime(df['Date'])
df.set_index("Date", inplace=True)
df['Close'] = df['Adj Close']
symbol_name = df['symbol'].iloc[0] # Assuming all rows have the same symbol
symbol_name = symbol_name.replace("BINANCE:", "")
symbol_name = symbol_name.replace("USDT.P", "/USDT:USDT")
df.drop(columns=['symbol'], inplace=True)
target_prediction_number = 2
time_periods = [6, 8, 10, 12, 14, 16, 18, 22, 26, 33, 44, 55]
name_periods = [6, 8, 10, 12, 14, 16, 18, 22, 26, 33, 44, 55]
new_columns = []
for period in time_periods:
for nperiod in name_periods:
df[f'ATR_{period}'] = ta.ATR(df['High'], df['Low'], df['Close'], timeperiod=period)
df[f'EMA_{period}'] = ta.EMA(df['Close'], timeperiod=period)
df[f'RSI_{period}'] = ta.RSI(df['Close'], timeperiod=period)
df[f'VWAP_{period}'] = ta.SUM(df['Volume'] * (df['High'] + df['Low'] + df['Close']) / 3, timeperiod=period) / ta.SUM(df['Volume'], timeperiod=period)
df[f'ROC_{period}'] = ta.ROC(df['Close'], timeperiod=period)
df[f'KC_upper_{period}'] = ta.EMA(df['High'], timeperiod=period)
df[f'KC_middle_{period}'] = ta.EMA(df['Low'], timeperiod=period)
df[f'Donchian_upper_{period}'] = ta.MAX(df['High'], timeperiod=period)
df[f'Donchian_lower_{period}'] = ta.MIN(df['Low'], timeperiod=period)
macd, macd_signal, _ = ta.MACD(df['Close'], fastperiod=(period + 12), slowperiod=(period + 26), signalperiod=(period + 9))
df[f'MACD_{period}'] = macd
df[f'MACD_signal_{period}'] = macd_signal
bb_upper, bb_middle, bb_lower = ta.BBANDS(df['Close'], timeperiod=period, nbdevup=2, nbdevdn=2)
df[f'BB_upper_{period}'] = bb_upper
df[f'BB_middle_{period}'] = bb_middle
df[f'BB_lower_{period}'] = bb_lower
df[f'EWO_{period}'] = ta.SMA(df['Close'], timeperiod=(period+5)) - ta.SMA(df['Close'], timeperiod=(period+35))
df["Returns"] = (df["Adj Close"] / df["Adj Close"].shift(target_prediction_number)) - 1
df["Range"] = (df["High"] / df["Low"]) - 1
df["Volatility"] = df['Returns'].rolling(window=target_prediction_number).std()
# Volume-Based Indicators
df['OBV'] = ta.OBV(df['Close'], df['Volume'])
df['ADL'] = ta.AD(df['High'], df['Low'], df['Close'], df['Volume'])
# Momentum-Based Indicators
df['Stoch_Oscillator'] = ta.STOCH(df['High'], df['Low'], df['Close'])[0]
df['PSAR'] = ta.SAR(df['High'], df['Low'], acceleration=0.02, maximum=0.2)
# More feature engineering...
timeframe_diff = df.index[-1] - df.index[-2]
timeframe = None
# Define timeframe based on time difference
if timeframe_diff == pd.Timedelta(minutes=1):
timeframe = '1m'
elif timeframe_diff == pd.Timedelta(minutes=3):
timeframe = '3m'
elif timeframe_diff == pd.Timedelta(minutes=5):
timeframe = '5m'
elif timeframe_diff == pd.Timedelta(minutes=15):
timeframe = '15m'
elif timeframe_diff == pd.Timedelta(minutes=30):
timeframe = '30m'
elif timeframe_diff == pd.Timedelta(minutes=45):
timeframe = '45m'
elif timeframe_diff == pd.Timedelta(hours=1):
timeframe = '1h'
elif timeframe_diff == pd.Timedelta(days=1):
timeframe = '1d'
elif timeframe_diff == pd.Timedelta(weeks=1):
timeframe = '1w'
else:
timeframe = 'Not sure'
# print('timeframe is - ', timeframe)
# Remove rows containing inf or nan values
df.dropna(inplace=True)
# Scaling
scaler = MinMaxScaler(feature_range=(0,1))
X = df.copy()
X_scale = scaler.fit_transform(X)
# Define a function to reshape the data
def reshape_data(data, time_steps):
samples = len(data) - time_steps + 1
reshaped_data = np.zeros((samples, time_steps, data.shape[1]))
for i in range(samples):
reshaped_data[i] = data[i:i + time_steps]
return reshaped_data
# Reshape the scaled X data
time_steps = 1 # Adjust the number of time steps as needed
X_reshaped = reshape_data(X_scale, time_steps)
# Now X_reshaped has the desired three-dimensional shape: (samples, time_steps, features)
# Each sample contains scaled data for a specific time window
X = X_reshaped
# Use the loaded model to predict on the entire dataset
df_ens = df.copy()
# df_ens['voting_classifier_ensembel_with_scale'] = np.argmax(model.predict(X), axis=1)
df_ens['voting_classifier_ensembel_with_scale'] = np.argmax(model.predict(X), axis=2)
df_ens['vcews'] = df_ens['voting_classifier_ensembel_with_scale'].shift(0).dropna().astype(int)
df_ens = df_ens.dropna()
# Backtesting
df_ens = df_ens.reset_index(inplace=False)
df_ens['Date'] = pd.to_datetime(df_ens['Date'])
df_ens.set_index('Date', inplace=True)
best_params = {'Optimizer': 'Return [%]',
'model_trained_on': model_name,
'OptimizerResult_Cross': 617.5341106880867,
'BEST_STOP_LOSS_sl_pct_long': 15,
'BEST_TAKE_PROFIT_tp_pct_long': 25,
'BEST_LIMIT_ORDER_limit_long': 24,
'BEST_STOP_LOSS_sl_pct_short': 15,
'BEST_TAKE_PROFIT_tp_pct_short': 25,
'BEST_LIMIT_ORDER_limit_short': 24,
'BEST_LEVERAGE_margin_leverage': 1,
'TRAILING_ACTIVATE_PCT': 10,
'TRAILING_STOP_PCT' : 5,
'roi_at_50' : 24,
'roi_at_100' : 20,
'roi_at_150' : 18,
'roi_at_200' : 15,
'roi_at_300' : 13,
'roi_at_500' : 10}
# Define SIGNAL_3 function
def SIGNAL_3(df_ens):
return df_ens['vcews']
# Define MyCandlesStrat_3 class
class MyCandlesStrat_3(Strategy):
sl_pct_l = best_params['BEST_STOP_LOSS_sl_pct_long']
tp_pct_l = best_params['BEST_TAKE_PROFIT_tp_pct_long']
limit_l = best_params['BEST_LIMIT_ORDER_limit_long']
sl_pct_s = best_params['BEST_STOP_LOSS_sl_pct_short']
tp_pct_s = best_params['BEST_TAKE_PROFIT_tp_pct_short']
limit_s = best_params['BEST_LIMIT_ORDER_limit_short']
margin_leverage = best_params['BEST_LEVERAGE_margin_leverage']
TRAILING_ACTIVATE_PCT = best_params['TRAILING_ACTIVATE_PCT']
TRAILING_STOP_PCT = best_params['TRAILING_STOP_PCT']
roi_at_50 = best_params['roi_at_50']
roi_at_100 = best_params['roi_at_100']
roi_at_150 = best_params['roi_at_150']
roi_at_200 = best_params['roi_at_200']
roi_at_300 = best_params['roi_at_300']
roi_at_500 = best_params['roi_at_500']
def init(self):
super().init()
self.signal1 = self.I(SIGNAL_3, self.data)
self.entry_time = Timestamp.now()
self.max_profit = 0
def next(self):
super().next()
if (self.signal1 == 1):
sl_price = self.data.Close[-1] * (1 - (self.sl_pct_l * 0.001))
tp_price = self.data.Close[-1] * (1 + (self.tp_pct_l * 0.001))
limit_price_l = tp_price * 0.994
self.position.is_long
self.buy(sl=sl_price, limit=limit_price_l, tp=tp_price)
if self.position.is_long:
self.entry_time = self.trades[0].entry_time # Accessing the current datetime
# Calculate current profit
# current_profit = self.trades[0].pl_pct
# Check for trailing stop loss based on current profit
if self.position and self.trades[0].pl_pct >= (self.TRAILING_ACTIVATE_PCT * 0.001):
self.max_profit = max(self.max_profit, self.trades[0].pl_pct)
trailing_stop_price = self.trades[0].entry_price * (1 + (self.max_profit - (self.TRAILING_STOP_PCT * 0.001)))
sl_price = min((self.data.Close[-1] * (1 - (self.TRAILING_STOP_PCT * 0.001))), trailing_stop_price)
time_spent_by_asset1 = (self.data.index[-1] - self.trades[0].entry_time).total_seconds() / 60
# Check for time interval-based selling
if self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 50) and (self.trades[0].pl_pct > (self.roi_at_50 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 50) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 100) and (self.trades[0].pl_pct > (self.roi_at_100 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 100) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 150) and (self.trades[0].pl_pct > (self.roi_at_150 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 150) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 200) and (self.trades[0].pl_pct > (self.roi_at_200 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 200) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 300) and (self.trades[0].pl_pct > (self.roi_at_300 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 300) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166< 950) and (self.trades[0].pl_pct > (self.roi_at_500 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166>= 950):
self.position.close()
elif (self.signal1 == 2):
sl_price = self.data.Close[-1] * (1 + (self.sl_pct_s * 0.001))
tp_price = self.data.Close[-1] * (1 - (self.tp_pct_s * 0.001))
limit_price_s = tp_price * 1.004
self.position.is_short
self.sell(sl=sl_price, limit=limit_price_s, tp=tp_price)
if self.position.is_short:
self.entry_time = self.trades[0].entry_time # Accessing the current datetime
# Calculate current profit
# current_profit = self.trades[0].pl_pct
# Check for trailing stop loss based on current profit
if self.position and self.trades[0].pl_pct >= (self.TRAILING_ACTIVATE_PCT * 0.001):
self.max_profit = max(self.max_profit, self.trades[0].pl_pct)
trailing_stop_price = self.trades[0].entry_price * (1 - (self.max_profit - (self.TRAILING_STOP_PCT * 0.001)))
sl_price = max((self.data.Close[-1] * (1 - (self.TRAILING_STOP_PCT * 0.001))), trailing_stop_price)
time_spent_by_asset1 = (self.data.index[-1] - self.trades[0].entry_time).total_seconds() / 60
# Check for time interval-based selling
if self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 50) and (self.trades[0].pl_pct > (self.roi_at_50 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 50) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 100) and (self.trades[0].pl_pct > (self.roi_at_100 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 100) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 150) and (self.trades[0].pl_pct > (self.roi_at_150 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 150) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 200) and (self.trades[0].pl_pct > (self.roi_at_200 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 200) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 300) and (self.trades[0].pl_pct > (self.roi_at_300 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 300) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166< 950) and (self.trades[0].pl_pct > (self.roi_at_500 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166>= 950):
self.position.close()
# Run backtest
bt_3 = Backtest(df_ens, MyCandlesStrat_3, cash=100000, commission=.001, margin= (1/MyCandlesStrat_3.margin_leverage), exclusive_orders=False)
stat_3 = bt_3.run()
print("backtest one done at 226 line - ", stat_3)
# custom_assets = {}
if ((stat_3['Return [%]'] > (stat_3['Buy & Hold Return [%]'] * 3))
& (stat_3['Profit Factor'] > 1.0)
& (stat_3['Max. Drawdown [%]'] > -40)
& (stat_3['Win Rate [%]'] > 55)
& (stat_3['Return [%]'] > 0)):
file_prefix = file_path.split('/')[-1].split('.')[0]
best_params = {'Optimizer': '1st backtest - Expectancy',
'model_trained_on': model_name,
'OptimizerResult_Cross': f"For {file_prefix}/USDT:USDT backtest was done from {stat_3['Start']} upto {stat_3['End']} for a duration of {stat_3['Duration']} using time frame of {timeframe} with Win Rate % - {round(stat_3['Win Rate [%]'],2)}, Return % - {round(stat_3['Return [%]'],3)},Expectancy % - {round(stat_3['Expectancy [%]'],5)} and Sharpe Ratio - {round(stat_3['Sharpe Ratio'],4)}.",
'BEST_STOP_LOSS_sl_pct_long': 15,
'BEST_TAKE_PROFIT_tp_pct_long': 25,
'BEST_LIMIT_ORDER_limit_long': 24,
'BEST_STOP_LOSS_sl_pct_short': 15,
'BEST_TAKE_PROFIT_tp_pct_short': 25,
'BEST_LIMIT_ORDER_limit_short': 24,
'BEST_LEVERAGE_margin_leverage': 1,
'TRAILING_ACTIVATE_PCT': 10,
'TRAILING_STOP_PCT' : 5,
'roi_at_50' : 24,
'roi_at_100' : 20,
'roi_at_150' : 18,
'roi_at_200' : 15,
'roi_at_300' : 13,
'roi_at_500' : 10}
key_mapping = {
'Optimizer': 'Optimizer_used',
'model_trained_on': 'model_name',
'OptimizerResult_Cross': 'Optimizer_result',
'BEST_STOP_LOSS_sl_pct_long': 'stop_loss_percent_long',
'BEST_TAKE_PROFIT_tp_pct_long': 'take_profit_percent_long',
'BEST_LIMIT_ORDER_limit_long': 'limit_long',
'BEST_STOP_LOSS_sl_pct_short': 'stop_loss_percent_short',
'BEST_TAKE_PROFIT_tp_pct_short': 'take_profit_percent_short',
'BEST_LIMIT_ORDER_limit_short': 'limit_short',
'BEST_LEVERAGE_margin_leverage': 'margin_leverage',
'TRAILING_ACTIVATE_PCT': 'TRAILING_ACTIVATE_PCT',
'TRAILING_STOP_PCT' : 'TRAILING_STOP_PCT',
'roi_at_50' : 'roi_at_50',
'roi_at_100' : 'roi_at_100',
'roi_at_150' :'roi_at_150',
'roi_at_200' : 'roi_at_200',
'roi_at_300' : 'roi_at_300',
'roi_at_500' : 'roi_at_500'
}
custom_assets = load_custom_assets()
transformed_params = {}
for old_key, value in best_params.items():
new_key = key_mapping.get(old_key, old_key)
transformed_params[new_key] = value
new_key = file_prefix + "/USDT:USDT"
# custom_assets[new_key] = transformed_params
# Update or add new entry to custom_assets
if new_key in custom_assets:
# Update existing entry
for key, value in transformed_params.items():
if isinstance(value, (int, float)) and key != 'margin_leverage' and value >= 1:
transformed_params[key] = round(transformed_params[key] * 0.001, 5)
custom_assets[new_key].update(transformed_params)
else:
# Add new entry
# Multiply numerical values by 0.001 for new entry if value > 1
for key, value in transformed_params.items():
if isinstance(value, (int, float)) and key != 'margin_leverage' and value >= 1:
transformed_params[key] = round(transformed_params[key] * 0.001, 5)
custom_assets[new_key] = transformed_params
# Save custom_assets to JSON file
save_custom_assets(custom_assets)
print(custom_assets)
else:
# Optimization
def optimize_strategy():
# Optimization Params
optimizer = 'Win Rate [%]'
stats = bt_3.optimize(
sl_pct_l = range(6,100, 2), # (5,10,15,20,25,30,40,50,75,100)
tp_pct_l = range(40,100, 2), # (0.005, 0.01, 0.015, 0.02, 0.025, 0.03, 0.04, 0.05, 0.075, 0.1)
# limit_l = (4,9,14,19,24,29,39,49,74,90),# (0.004, 0.009, 0.014, 0.019, 0.024, 0.029, 0.039, 0.049, 0.074, 0.09)
sl_pct_s = range(6,100, 2),
tp_pct_s = range(40,100, 2),
# limit_s = (4,9,14,19,24,29,39,49,74,90),
margin_leverage = range(1, 8),
TRAILING_ACTIVATE_PCT = range(6,100,2),
TRAILING_STOP_PCT = range(6,100,2),
roi_at_50 = range(6,100,2),
roi_at_100 = range(6,100,2),
roi_at_150 = range(6,100,2),
roi_at_200 = range(6,100,2),
roi_at_300 = range(6,100,2),
roi_at_500 = range(6,100,2),
constraint=lambda p: ( (p.sl_pct_l > (p.tp_pct_l) ) and
((p.sl_pct_s) > (p.tp_pct_s)) and
(p.roi_at_50 > p.roi_at_100) and (p.roi_at_100 > p.roi_at_150) and
(p.roi_at_150 > p.roi_at_200) and (p.roi_at_200 > p.roi_at_300) and (p.roi_at_300 > p.roi_at_500) and
(p.TRAILING_ACTIVATE_PCT > p.TRAILING_STOP_PCT)),
maximize = optimizer,
return_optimization=True,
method = 'skopt',
max_tries = 120 # 20% for 0.2 and 100% for 1.0, this applys when not using 'skopt' method, for 'skopt' number starts from 1 to 200 max epochs
)
# Extract the optimization results
best_params = {
'Optimizer': optimizer,
'model_trained_on': model_name,
'OptimizerResult_Cross': stats[0][optimizer],
'BEST_STOP_LOSS_sl_pct_long': stats[1].x[0],
'BEST_TAKE_PROFIT_tp_pct_long': stats[1].x[1] ,
'BEST_LIMIT_ORDER_limit_long': stats[1].x[1] * 0.997,
'BEST_STOP_LOSS_sl_pct_short': stats[1].x[2] ,
'BEST_TAKE_PROFIT_tp_pct_short': stats[1].x[3] ,
'BEST_LIMIT_ORDER_limit_short': stats[1].x[3] * 0.997,
'BEST_LEVERAGE_margin_leverage': stats[1].x[4],
'TRAILING_ACTIVATE_PCT': stats[1].x[5],
'TRAILING_STOP_PCT' : stats[1].x[6],
'roi_at_50' : stats[1].x[7],
'roi_at_100' : stats[1].x[8],
'roi_at_150' : stats[1].x[9],
'roi_at_200' : stats[1].x[10],
'roi_at_300' : stats[1].x[11],
'roi_at_500' : stats[1].x[12]
# 'BEST_STOP_LOSS_sl_pct_long': stats._strategy.sl_pct_l,
# 'BEST_TAKE_PROFIT_tp_pct_long': stats._strategy.tp_pct_l,
# 'BEST_LIMIT_ORDER_limit_long': stats._strategy.tp_pct_l * 0.998,
# 'BEST_STOP_LOSS_sl_pct_short': stats._strategy.sl_pct_s,
# 'BEST_TAKE_PROFIT_tp_pct_short': stats._strategy.tp_pct_s,
# 'BEST_LIMIT_ORDER_limit_short': stats._strategy.sl_pct_s * 0.998,
# 'BEST_LEVERAGE_margin_leverage': stats._strategy.margin_leverage
}
return best_params
# Obtain best parameters
best_params = optimize_strategy()
print("best_params line 322 ", best_params)
if best_params:
print(best_params)
else:
best_params = {'Optimizer': 'Return [%]',
'model_trained_on': model_name,
'OptimizerResult_Cross': 617.5341106880867,
'BEST_STOP_LOSS_sl_pct_long': 0.025,
'BEST_TAKE_PROFIT_tp_pct_long': 0.025,
'BEST_LIMIT_ORDER_limit_long': 0.024,
'BEST_STOP_LOSS_sl_pct_short': 0.025,
'BEST_TAKE_PROFIT_tp_pct_short': 0.025,
'BEST_LIMIT_ORDER_limit_short': 0.024,
'TRAILING_ACTIVATE_PCT': 10,
'TRAILING_STOP_PCT' : 5,
'roi_at_50' : 24,
'roi_at_100' : 2,
'roi_at_150' : 18,
'roi_at_200' : 15,
'roi_at_300' : 13,
'roi_at_500' : 10}
# Define SIGNAL_11 function
def SIGNAL_11(df_ens):
return df_ens['vcews']
# Define MyCandlesStrat_11 class
class MyCandlesStrat_11(Strategy):
sl_pct_l = best_params['BEST_STOP_LOSS_sl_pct_long']
tp_pct_l = best_params['BEST_TAKE_PROFIT_tp_pct_long']
limit_l = best_params['BEST_LIMIT_ORDER_limit_long']
sl_pct_s = best_params['BEST_STOP_LOSS_sl_pct_short']
tp_pct_s = best_params['BEST_TAKE_PROFIT_tp_pct_short']
limit_s = best_params['BEST_LIMIT_ORDER_limit_short']
margin_leverage = best_params['BEST_LEVERAGE_margin_leverage']
TRAILING_ACTIVATE_PCT = best_params['TRAILING_ACTIVATE_PCT']
TRAILING_STOP_PCT = best_params['TRAILING_STOP_PCT']
roi_at_50 = best_params['roi_at_50']
roi_at_100 = best_params['roi_at_100']
roi_at_150 = best_params['roi_at_150']
roi_at_200 = best_params['roi_at_200']
roi_at_300 = best_params['roi_at_300']
roi_at_500 = best_params['roi_at_500']
def init(self):
super().init()
self.signal1 = self.I(SIGNAL_11, self.data)
self.entry_time = Timestamp.now()
self.max_profit = 0
def next(self):
super().next()
if (self.signal1 == 1):
sl_price = self.data.Close[-1] * (1 - (self.sl_pct_l * 0.001))
tp_price = self.data.Close[-1] * (1 + (self.tp_pct_l * 0.001))
limit_price_l = tp_price * 0.994
self.position.is_long
self.buy(sl=sl_price, limit=limit_price_l, tp=tp_price)
if self.position.is_long:
self.entry_time = self.trades[0].entry_time # Accessing the current datetime
# Calculate current profit
# current_profit = self.trades[0].pl_pct
# Check for trailing stop loss based on current profit
if self.position and self.trades[0].pl_pct >= (self.TRAILING_ACTIVATE_PCT * 0.001):
self.max_profit = max(self.max_profit, self.trades[0].pl_pct)
trailing_stop_price = self.trades[0].entry_price * (1 + (self.max_profit - (self.TRAILING_STOP_PCT * 0.001)))
sl_price = min((self.data.Close[-1] * (1 - (self.TRAILING_STOP_PCT * 0.001))), trailing_stop_price)
# time_spent_by_asset1 = (self.data.index[-1] - self.trades[0].entry_time).total_seconds() / 60
# Check for time interval-based selling
if self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 50) and (self.trades[0].pl_pct > (self.roi_at_50 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 50) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 100) and (self.trades[0].pl_pct > (self.roi_at_100 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 100) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 150) and (self.trades[0].pl_pct > (self.roi_at_150 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 150) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 200) and (self.trades[0].pl_pct > (self.roi_at_200 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 200) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 300) and (self.trades[0].pl_pct > (self.roi_at_300 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 300) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166< 950) and (self.trades[0].pl_pct > (self.roi_at_500 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166>= 950):
self.position.close()
elif (self.signal1 == 2):
sl_price = self.data.Close[-1] * (1 + (self.sl_pct_s * 0.001))
tp_price = self.data.Close[-1] * (1 - (self.tp_pct_s * 0.001))
limit_price_s = tp_price * 1.004
self.position.is_short
self.sell(sl=sl_price, limit=limit_price_s, tp=tp_price)
if self.position.is_short:
self.entry_time = self.trades[0].entry_time # Accessing the current datetime
# Calculate current profit
# current_profit = self.trades[0].pl_pct
# Check for trailing stop loss based on current profit
if self.position and self.trades[0].pl_pct >= (self.TRAILING_ACTIVATE_PCT * 0.001):
self.max_profit = max(self.max_profit, self.trades[0].pl_pct)
trailing_stop_price = self.trades[0].entry_price * (1 - (self.max_profit - (self.TRAILING_STOP_PCT * 0.001)))
sl_price = max((self.data.Close[-1] * (1 - (self.TRAILING_STOP_PCT * 0.001))), trailing_stop_price)
time_spent_by_asset1 = (self.data.index[-1] - self.trades[0].entry_time).total_seconds() / 60
# Check for time interval-based selling
if self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 50) and (self.trades[0].pl_pct > (self.roi_at_50 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 50) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 100) and (self.trades[0].pl_pct > (self.roi_at_100 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 100) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 150) and (self.trades[0].pl_pct > (self.roi_at_150 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 150) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 200) and (self.trades[0].pl_pct > (self.roi_at_200 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 200) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166<= 300) and (self.trades[0].pl_pct > (self.roi_at_300 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166> 300) and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166< 950) and (self.trades[0].pl_pct > (self.roi_at_500 * 0.001)):
self.position.close()
elif self.position and ((self.data.index[-1] - self.trades[0].entry_time).total_seconds() * 0.0166>= 950):
self.position.close()
# Run backtest with optimized parameters
bt_11 = Backtest(df_ens, MyCandlesStrat_11, cash=100000, commission=.001, margin=(1 / MyCandlesStrat_11.margin_leverage), exclusive_orders=False)
stat_11 = bt_11.run()
print("stat_11 line 388 - ", stat_11)
# Additional processing for custom_assets
# custom_assets = {}
if ((stat_11['Return [%]'] > (stat_11['Buy & Hold Return [%]'] * 3))
& (stat_11['Profit Factor'] > 1.0)
& (stat_11['Max. Drawdown [%]'] > -35)
& (stat_11['Win Rate [%]'] > 52)
& (stat_11['Return [%]'] > 0)):
file_prefix = file_path.split('/')[-1].split('.')[0]
print(f"second backtest success for {file_prefix}/USDT:USDT with Win Rate % of {stat_11['Win Rate [%]']} and with Return in % of {stat_11['Return [%]']}" )
best_params = {'Optimizer': '2nd backtest with Expectancy',
# 'OptimizerResult_Cross': f"2nd backtest, Sharpe Ratio - {stat_11['Sharpe Ratio']}, Returns % - {stat_11['Return [%]']}, Win Rate % - {stat_11['Win Rate [%]']}",
'model_trained_on': model_name,
'OptimizerResult_Cross': f"For {file_prefix}/USDT:USDT backtest was done from {stat_11['Start']} upto {stat_11['End']} for a duration of {stat_11['Duration']} using time frame of {timeframe} with Win Rate % - {round(stat_11['Win Rate [%]'],2)}, Return % - {round(stat_11['Return [%]'],3)}, Expectancy % - {round(stat_11['Expectancy [%]'],5)} and Sharpe Ratio - {round(stat_11['Sharpe Ratio'],3)}.",
'BEST_STOP_LOSS_sl_pct_long': MyCandlesStrat_11.sl_pct_l.tolist(),
'BEST_TAKE_PROFIT_tp_pct_long': MyCandlesStrat_11.tp_pct_l.tolist(),
'BEST_LIMIT_ORDER_limit_long': round(MyCandlesStrat_11.tp_pct_l.tolist() * 0.996, 2),
'BEST_STOP_LOSS_sl_pct_short': MyCandlesStrat_11.sl_pct_s.tolist(),
'BEST_TAKE_PROFIT_tp_pct_short': MyCandlesStrat_11.tp_pct_s.tolist(),
'BEST_LIMIT_ORDER_limit_short': round(MyCandlesStrat_11.sl_pct_s.tolist() * 0.996,2),
'BEST_LEVERAGE_margin_leverage': MyCandlesStrat_11.margin_leverage.tolist(),
'TRAILING_ACTIVATE_PCT': MyCandlesStrat_11.TRAILING_ACTIVATE_PCT.tolist(),
'TRAILING_STOP_PCT' : MyCandlesStrat_11.TRAILING_STOP_PCT.tolist(),
'roi_at_50' : MyCandlesStrat_11.roi_at_50.tolist(),
'roi_at_100' : MyCandlesStrat_11.roi_at_100.tolist(),
'roi_at_150' :MyCandlesStrat_11.roi_at_150.tolist(),
'roi_at_200' : MyCandlesStrat_11.roi_at_200.tolist(),
'roi_at_300' : MyCandlesStrat_11.roi_at_300.tolist(),
'roi_at_500' : MyCandlesStrat_11.roi_at_500.tolist()
}
# print("best_params under stat_11 ", best_params)
key_mapping = {
'Optimizer': 'Optimizer_used',
'model_trained_on': 'model_name',
'OptimizerResult_Cross': 'Optimizer_result',
'BEST_STOP_LOSS_sl_pct_long': 'stop_loss_percent_long',
'BEST_TAKE_PROFIT_tp_pct_long': 'take_profit_percent_long',
'BEST_LIMIT_ORDER_limit_long': 'limit_long',
'BEST_STOP_LOSS_sl_pct_short': 'stop_loss_percent_short',
'BEST_TAKE_PROFIT_tp_pct_short': 'take_profit_percent_short',
'BEST_LIMIT_ORDER_limit_short': 'limit_short',
'BEST_LEVERAGE_margin_leverage': 'margin_leverage',
'TRAILING_ACTIVATE_PCT': 'TRAILING_ACTIVATE_PCT',
'TRAILING_STOP_PCT' : 'TRAILING_STOP_PCT',
'roi_at_50' : 'roi_at_50',
'roi_at_100' : 'roi_at_100',
'roi_at_150' :'roi_at_150',
'roi_at_200' : 'roi_at_200',
'roi_at_300' : 'roi_at_300',
'roi_at_500' : 'roi_at_500'
}
# Update or add new entry to custom_assets
custom_assets = load_custom_assets()
transformed_params = {}
for old_key, value in best_params.items():
new_key = key_mapping.get(old_key, old_key)
transformed_params[new_key] = value
new_key = file_prefix + "/USDT:USDT"
# custom_assets[new_key] = transformed_params
if new_key in custom_assets:
# Update existing entry
for key, value in transformed_params.items():
if isinstance(value, (int, float)) and key != 'margin_leverage' and value >= 1:
transformed_params[key] = round(transformed_params[key] * 0.001, 5)
custom_assets[new_key].update(transformed_params)
else:
# Add new entry
# Multiply numerical values by 0.001 for new entry if value > 1
for key, value in transformed_params.items():
if isinstance(value, (int, float)) and key != 'margin_leverage' and value >= 1:
transformed_params[key] = round(transformed_params[key] * 0.001, 5)
custom_assets[new_key] = transformed_params
# Save custom_assets to JSON file
save_custom_assets(custom_assets)
print("custom_assets after save ", custom_assets)
return df, symbol_name, custom_assets
# except Exception as e:
# # Print the error message
# print(f"Error processing {file_path}: {e}")
# print("custom assets at error level line 361 ", custom_assets)
# # Return None for both DataFrame and symbol name to indicate failure
# return None, symbol_name, custom_assets
# Define a thread worker function
def thread_worker(file):
result = process_json(file)
return result
def main():
# Get a list of all JSON files in the folder
# NOTE: make sure to mention the tradingview downloaded data folder here
json_files = [f"./tradingview_crypto_assets_15m/{file}" for file in os.listdir("./tradingview_crypto_assets_15m/") if file.endswith(".json")]
# print(json_files)
# Get the number of available CPU cores
num_cores = os.cpu_count()
# print(num_cores)
# Set the max_workers parameter based on the number of CPU cores
max_workers = (num_cores) if (num_cores > 1) else 1 # Default to 1 if CPU count cannot be determined
# max_workers = 1 # Default to 1 if CPU count cannot be determined
print('max workers (Total Number of CPU cores to be used) - ', max_workers)
# Process JSON files in parallel using multi-core processing
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# Submit threads for each JSON file
futures = [executor.submit(thread_worker, file) for file in json_files]
# Wait for all threads to complete
results = [future.result() for future in futures]
# Process the results as needed
for result in results:
if result is None:
continue
df, symbol_name, custom_assets = result
print(f"Processed {symbol_name}")
print(f'custom_assets ', custom_assets)
if custom_data: # Check if custom_data is not None
custom_assets.update(custom_data)
# Define a function to continuously run the loop
def run_continuous_loop():
while True:
main()
# Start the continuous loop in a separate thread
thread = threading.Thread(target=run_continuous_loop)
thread.start()output:
max workers (Total Number of CPU cores to be used) - 4
219/219 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step
219/219 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step
219/219 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step
219/219 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step
backtest one done at 226 line - Start 2024-03-02 11:45:00
End 2024-05-14 03:45:00
Duration 72 days 16:00:00
Exposure Time [%] 85.237208
Equity Final [$] 45917.74697
Equity Peak [$] 119511.93047
Return [%] -54.082253
Buy & Hold Return [%] -27.134777
Return (Ann.) [%] -98.222272
Volatility (Ann.) [%] 3.390676
Sharpe Ratio 0.0
Sortino Ratio 0.0
Calmar Ratio 0.0
Max. Drawdown [%] -63.780594
Avg. Drawdown [%] -7.944307
Max. Drawdown Duration 65 days 12:15:00
Avg. Drawdown Duration 6 days 13:06:00
# Trades 704
Win Rate [%] 42.471591
Best Trade [%] 7.078622
Worst Trade [%] -5.342172
Avg. Trade [%] -0.100692
Max. Trade Duration 0 days 16:00:00
Avg. Trade Duration 0 days 02:09:00
Profit Factor 0.910244
Expectancy [%] -0.083294
SQN -1.448338
_strategy MyCandlesStrat_3
_equity_curve ...
_trades Size Ent...
dtype: object219/219 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step
219/219 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step
219/219 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step
219/219 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step
backtest one done at 226 line - Start 2024-03-02 11:45:00
End 2024-05-14 03:45:00
Duration 72 days 16:00:00
Exposure Time [%] 66.332234
Equity Final [$] 71540.222404
Equity Peak [$] 104167.687582
Return [%] -28.459778
Buy & Hold Return [%] -7.367375
Return (Ann.) [%] -84.223673
Volatility (Ann.) [%] 22.572365
Sharpe Ratio 0.0
Sortino Ratio 0.0
Calmar Ratio 0.0
Max. Drawdown [%] -51.37295
Avg. Drawdown [%] -27.548884
Max. Drawdown Duration 72 days 04:15:00
Avg. Drawdown Duration 36 days 07:23:00
# Trades 194
Win Rate [%] 67.525773
Best Trade [%] 5.416101
Worst Trade [%] -5.321366
Avg. Trade [%] 0.213571
Max. Trade Duration 3 days 06:15:00
Avg. Trade Duration 0 days 09:34:00
Profit Factor 1.200713
Expectancy [%] 0.280423
SQN -0.892377
_strategy MyCandlesStrat_3
_equity_curve ...
_trades Size Entry...
dtype: object
backtest one done at 226 line - Start 2024-03-02 11:45:00
End 2024-05-14 03:45:00
Duration 72 days 16:00:00
Exposure Time [%] 91.299986
Equity Final [$] 130059.0093
Equity Peak [$] 134623.59371
Return [%] 30.059009
Buy & Hold Return [%] -22.347518
Return (Ann.) [%] 201.316051
Volatility (Ann.) [%] 304.038082
Sharpe Ratio 0.662141
Sortino Ratio 3.673322
Calmar Ratio 7.803374
Max. Drawdown [%] -25.798591
Avg. Drawdown [%] -3.662406
Max. Drawdown Duration 40 days 01:45:00
Avg. Drawdown Duration 2 days 09:32:00
# Trades 267
Win Rate [%] 68.539326
Best Trade [%] 5.435705
Worst Trade [%] -5.361912
Avg. Trade [%] 0.352395
Max. Trade Duration 2 days 23:30:00
Avg. Trade Duration 0 days 10:46:00
Profit Factor 1.355785
Expectancy [%] 0.405569
SQN 0.691026
_strategy MyCandlesStrat_3
_equity_curve ...
_trades Size Entry...
dtype: object
{'QNT/USDT:USDT': {'Optimizer_used': '1st backtest - Expectancy', 'model_name': 'cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.91_time_20240516025817.keras', 'Optimizer_result': 'For QNT/USDT:USDT backtest was done from 2024-03-02 11:45:00 upto 2024-05-14 03:45:00 for a duration of 72 days 16:00:00 using time frame of 15m with Win Rate % - 68.54, Return % - 30.059,Expectancy % - 0.40557 and Sharpe Ratio - 0.6621.', 'stop_loss_percent_long': 0.052, 'take_profit_percent_long': 0.055, 'limit_long': 0.054, 'stop_loss_percent_short': 0.052, 'take_profit_percent_short': 0.055, 'limit_short': 0.054, 'margin_leverage': 1, 'TRAILING_ACTIVATE_PCT': 0.045, 'TRAILING_STOP_PCT': 0.005, 'roi_at_50': 0.054, 'roi_at_100': 0.05, 'roi_at_150': 0.045, 'roi_at_200': 0.04, 'roi_at_300': 0.03, 'roi_at_500': 0.01}}
backtest one done at 226 line - Start 2024-03-02 11:45:00
End 2024-05-14 03:45:00
Duration 72 days 16:00:00
Exposure Time [%] 72.710334
Equity Final [$] 120933.565868
Equity Peak [$] 175382.890316
Return [%] 20.933566
Buy & Hold Return [%] 10.347826
Return (Ann.) [%] 123.644543
Volatility (Ann.) [%] 997.602729
Sharpe Ratio 0.123942
Sortino Ratio 1.746241
Calmar Ratio 2.495813
Max. Drawdown [%] -49.540787
Avg. Drawdown [%] -7.082874
Max. Drawdown Duration 38 days 02:30:00
Avg. Drawdown Duration 2 days 21:06:00
# Trades 159
Win Rate [%] 55.345912
Best Trade [%] 17.226306
Worst Trade [%] -5.328038
Avg. Trade [%] 0.357529
Max. Trade Duration 3 days 10:30:00
Avg. Trade Duration 0 days 08:54:00
Profit Factor 1.220746
Expectancy [%] 0.490183
SQN 0.275209
_strategy MyCandlesStrat_3
_equity_curve ...
_trades Size Ent...
dtype: object
backtest one done at 226 line - Start 2024-03-02 11:45:00
End 2024-05-14 03:45:00
Duration 72 days 16:00:00
Exposure Time [%] 78.859108
Equity Final [$] 89782.288674
Equity Peak [$] 199863.063254
Return [%] -10.217711
Buy & Hold Return [%] -27.134777
Return (Ann.) [%] -48.716197
Volatility (Ann.) [%] 90.146634
Sharpe Ratio 0.0
Sortino Ratio 0.0
Calmar Ratio 0.0
Max. Drawdown [%] -55.078098
Avg. Drawdown [%] -3.816866
Max. Drawdown Duration 40 days 14:15:00
Avg. Drawdown Duration 1 days 08:00:00
# Trades 129
Win Rate [%] 56.589147
Best Trade [%] 5.476307
Worst Trade [%] -5.701131
Avg. Trade [%] 0.040376
Max. Trade Duration 2 days 19:15:00
Avg. Trade Duration 0 days 14:21:00
Profit Factor 1.072351
Expectancy [%] 0.136691
SQN -0.153638
_strategy MyCandlesStrat_3
_equity_curve ...
_trades Size Ent...
dtype: objec
Backtest.optimize: 0%| | 0/120 [00:00<?, ?it/s]
Backtest.optimize: 0%| | 0/120 [00:00<?, ?it/s]
Backtest.optimize: 0%| | 0/120 [00:00<?, ?it/s]
.................................................................................................................................
(output goes on for all the assets and then short listed assets get saved inside custom_assets.txt)
Youtube Link Explanation of VishvaAlgo v4.x Features — Link
get entire code and profitable algos @ https://patreon.com/pppicasso
The provided Python code appears to be related to backtesting a cryptocurrency trading strategy. Here’s a breakdown of the code functionalities:
Data Processing:
- Function
process_json: This function reads a JSON file containing cryptocurrency price data. - Data Cleaning and Transformation: It cleans and transforms the data by:
- Renaming columns to standard names (e.g., ‘date’ to ‘Date’).
- Converting the ‘Date’ column to datetime format.
- Setting ‘Date’ as the index.
- Filling missing values in the ‘Close’ column with the previous close price.
- Extracting the symbol name from the ‘symbol’ column.
- Technical Indicator Calculation: The script calculates various technical indicators like ATR, EMA, RSI, etc., using the
talibrary (assumed to be imported). - Feature Engineering: It creates additional features like returns, volatility, volume-based indicators, and momentum-based indicators.
- Data Scaling: The script scales the data using
MinMaxScalerfor better model performance during backtesting. - Reshaping Data: The data is reshaped into a format suitable for the trading strategy (e.g., sequences of past price data).
Backtesting Strategy:
- Function
SIGNAL_3: This function likely defines the trading signals based on some criteria (not shown in the provided code). - Class
MyCandlesStrat_3: This class defines the trading strategy using theBacktraderlibrary (assumed to be imported). Key elements include:
- Stop-loss and Take-profit: These are set based on predefined percentages (
BEST_STOP_LOSS_sl_pct_long, etc.) for long and short positions. - Limit orders: These are used to ensure order execution within a specific price range.
- Trailing Stop-loss: The stop-loss is dynamically adjusted based on current profit to lock in gains.
- Time-based profit taking: Profits are automatically locked in after a certain time holding the asset.
- Leverage: The strategy uses a predefined leverage multiplier (
BEST_LEVERAGE_margin_leverage).
Backtesting and Analysis:
- Backtest: The script performs a backtest on the processed data using the
MyCandlesStrat_3strategy with a starting capital of 100000. - Performance Metrics: Backtesting results likely include various performance metrics like returns, Sharpe Ratio, Win Rate, and Drawdown (not explicitly shown in the provided code).
Conditional Logic:
- The script checks if certain performance conditions are met (high return, good profit factor, etc.).
- If the conditions are satisfied, the script potentially saves the trading strategy parameters for this specific asset.
Usage of ThreadPoolExecutor class for parallel processing of JSON files. Here's a breakdown of its functionality:
1. Thread Worker Function (thread_worker):
- This function takes a single JSON file path as input (
file). - It calls the
process_jsonfunction (assumed to be defined elsewhere) to process the JSON data. - It returns the processed result, likely a Pandas DataFrame (
df), symbol name (symbol_name), and potentially other custom data (custom_assets).
2. Main Function (main):
- It retrieves a list of all JSON files within a specified folder (
./tradingview_crypto_assets_15m/). - It determines the number of available CPU cores using
os.cpu_count(). - It sets the
max_workersparameter for theThreadPoolExecutorbased on the CPU cores (using all cores if available, defaulting to 1 otherwise). - It prints the number of cores to be used for processing.
- It creates a
ThreadPoolExecutorwith the determinedmax_workers. - It iterates through the list of JSON files and submits each file path to the thread pool using
executor.submit(thread_worker, file). This creates tasks for each file to be processed concurrently. - It waits for all submitted tasks (futures) to complete using
future.result()and stores the results in a list (results). - It iterates through the processing results:
- If a result is
None, it skips to the next iteration (potentially handling errors). - Otherwise, it unpacks the result (
df,symbol_name, and potentiallycustom_assets). - It prints information about the processed symbol and the custom assets (if any).
- It conditionally updates
custom_assetswith additional custom data (custom_data) if it exists (logic not entirely shown).
3. Continuous Loop Function (run_continuous_loop):
- This function defines an infinite loop (
while True). - Inside the loop, it calls the
mainfunction, presumably to process a batch of JSON files repeatedly.
4. Starting the Loop:
- The code creates a separate thread using
threading.Threadand sets its target to therun_continuous_loopfunction. - Finally, it starts the thread, initiating the continuous processing loop.
Overall, this code snippet demonstrates parallel processing of JSON files using a thread pool based on CPU cores. The loop continuously processes batches of files.
The code demonstrates a framework for backtesting a cryptocurrency trading strategy that uses technical indicators and incorporates risk management techniques like stop-loss and trailing stop-loss.
Disclaimer:
- Always remeber that, Backtesting results may not be indicative of future performance.
- Trading cryptocurrencies involves significant risks, and you should always do your own research before making any investment decisions.
custom_assets.txt Output:
{
"QNT/USDT:USDT": {
"Optimizer_used": "1st backtest - Expectancy",
"model_name": "cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.91_time_20240516025817.keras",
"Optimizer_result": "For QNT/USDT:USDT backtest was done from 2024-03-02 11:45:00 upto 2024-05-14 03:45:00 for a duration of 72 days 16:00:00 using time frame of 15m with Win Rate % - 68.54, Return % - 30.059,Expectancy % - 0.40557 and Sharpe Ratio - 0.6621.",
"stop_loss_percent_long": 0.052,
"take_profit_percent_long": 0.055,
"limit_long": 0.054,
"stop_loss_percent_short": 0.052,
"take_profit_percent_short": 0.055,
"limit_short": 0.054,
"margin_leverage": 1,
"TRAILING_ACTIVATE_PCT": 0.045,
"TRAILING_STOP_PCT": 0.005,
"roi_at_50": 0.054,
"roi_at_100": 0.05,
"roi_at_150": 0.045,
"roi_at_200": 0.04,
"roi_at_300": 0.03,
"roi_at_500": 0.01
},
"NMR/USDT:USDT": {
"Optimizer_used": "1st backtest - Expectancy",
"model_name": "cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.91_time_20240516025817.keras",
"Optimizer_result": "For NMR/USDT:USDT backtest was done from 2024-03-02 11:45:00 upto 2024-05-14 03:45:00 for a duration of 72 days 16:00:00 using time frame of 15m with Win Rate % - 64.15, Return % - 58.843,Expectancy % - 0.81714 and Sharpe Ratio - 0.7911.",
"stop_loss_percent_long": 0.052,
"take_profit_percent_long": 0.055,
"limit_long": 0.054,
"stop_loss_percent_short": 0.052,
"take_profit_percent_short": 0.055,
"limit_short": 0.054,
"margin_leverage": 1,
"TRAILING_ACTIVATE_PCT": 0.045,
"TRAILING_STOP_PCT": 0.005,
"roi_at_50": 0.054,
"roi_at_100": 0.05,
"roi_at_150": 0.045,
"roi_at_200": 0.04,
"roi_at_300": 0.03,
"roi_at_500": 0.01
},
"BNT/USDT:USDT": {
"Optimizer_used": "1st backtest - Expectancy",
"model_name": "cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.91_time_20240516025817.keras",
"Optimizer_result": "For BNT/USDT:USDT backtest was done from 2024-03-02 11:45:00 upto 2024-05-14 03:45:00 for a duration of 72 days 16:00:00 using time frame of 15m with Win Rate % - 59.86, Return % - 25.737,Expectancy % - 0.50737 and Sharpe Ratio - 0.6972.",
"stop_loss_percent_long": 0.052,
"take_profit_percent_long": 0.055,
"limit_long": 0.054,
"stop_loss_percent_short": 0.052,
"take_profit_percent_short": 0.055,
"limit_short": 0.054,
"margin_leverage": 1,
"TRAILING_ACTIVATE_PCT": 0.045,
"TRAILING_STOP_PCT": 0.005,
"roi_at_50": 0.054,
"roi_at_100": 0.05,
"roi_at_150": 0.045,
"roi_at_200": 0.04,
"roi_at_300": 0.03,
"roi_at_500": 0.01
},
"GMX/USDT:USDT": {
"Optimizer_used": "1st backtest - Expectancy",
"model_name": "cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.91_time_20240516025817.keras",
"Optimizer_result": "For GMX/USDT:USDT backtest was done from 2024-03-02 11:45:00 upto 2024-05-14 03:45:00 for a duration of 72 days 16:00:00 using time frame of 15m with Win Rate % - 65.38, Return % - 48.712,Expectancy % - 1.00621 and Sharpe Ratio - 1.293.",
"stop_loss_percent_long": 0.052,
"take_profit_percent_long": 0.055,
"limit_long": 0.054,
"stop_loss_percent_short": 0.052,
"take_profit_percent_short": 0.055,
"limit_short": 0.054,
"margin_leverage": 1,
"TRAILING_ACTIVATE_PCT": 0.045,
"TRAILING_STOP_PCT": 0.005,
"roi_at_50": 0.054,
"roi_at_100": 0.05,
"roi_at_150": 0.045,
"roi_at_200": 0.04,
"roi_at_300": 0.03,
"roi_at_500": 0.01
},
"T/USDT:USDT": {
"Optimizer_used": "1st backtest - Expectancy",
"model_name": "cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.91_time_20240516025817.keras",
"Optimizer_result": "For T/USDT:USDT backtest was done from 2024-03-02 11:45:00 upto 2024-05-14 03:45:00 for a duration of 72 days 16:00:00 using time frame of 15m with Win Rate % - 64.71, Return % - 133.093,Expectancy % - 1.47402 and Sharpe Ratio - 0.596.",
"stop_loss_percent_long": 0.052,
"take_profit_percent_long": 0.055,
"limit_long": 0.054,
"stop_loss_percent_short": 0.052,
"take_profit_percent_short": 0.055,
"limit_short": 0.054,
"margin_leverage": 1,
"TRAILING_ACTIVATE_PCT": 0.045,
"TRAILING_STOP_PCT": 0.005,
"roi_at_50": 0.054,
"roi_at_100": 0.05,
"roi_at_150": 0.045,
"roi_at_200": 0.04,
"roi_at_300": 0.03,
"roi_at_500": 0.01
},
"MATIC/USDT:USDT": {
"Optimizer_used": "1st backtest - Expectancy",
"model_name": "cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.91_time_20240516025817.keras",
"Optimizer_result": "For MATIC/USDT:USDT backtest was done from 2024-03-02 11:45:00 upto 2024-05-14 03:45:00 for a duration of 72 days 16:00:00 using time frame of 15m with Win Rate % - 66.9, Return % - 47.395,Expectancy % - 0.31207 and Sharpe Ratio - 0.7049.",
"stop_loss_percent_long": 0.052,
"take_profit_percent_long": 0.055,
"limit_long": 0.054,
"stop_loss_percent_short": 0.052,
"take_profit_percent_short": 0.055,
"limit_short": 0.054,
"margin_leverage": 1,
"TRAILING_ACTIVATE_PCT": 0.045,
"TRAILING_STOP_PCT": 0.005,
"roi_at_50": 0.054,
"roi_at_100": 0.05,
"roi_at_150": 0.045,
"roi_at_200": 0.04,
"roi_at_300": 0.03,
"roi_at_500": 0.01
},
"OP/USDT:USDT": {
"Optimizer_used": "2nd backtest with Expectancy",
"model_name": "cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.91_time_20240516025817.keras",
"Optimizer_result": "For OP/USDT:USDT backtest was done from 2024-03-02 11:45:00 upto 2024-05-14 03:45:00 for a duration of 72 days 16:00:00 using time frame of 15m with Win Rate % - 60.0, Return % - 67.048, Expectancy % - 0.57196 and Sharpe Ratio - 0.599.",
"stop_loss_percent_long": 0.034,
"take_profit_percent_long": 0.058,
"limit_long": 0.05777,
"stop_loss_percent_short": 0.092,
"take_profit_percent_short": 0.081,
"limit_short": 0.09163,
"margin_leverage": 1,
"TRAILING_ACTIVATE_PCT": 0.061,
"TRAILING_STOP_PCT": 0.062,
"roi_at_50": 0.06,
"roi_at_100": 0.046,
"roi_at_150": 0.052,
"roi_at_200": 0.028,
"roi_at_300": 0.018,
"roi_at_500": 0.024
},
"ENJ/USDT:USDT": {
"Optimizer_used": "1st backtest - Expectancy",
"model_name": "cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.91_time_20240516025817.keras",
"Optimizer_result": "For ENJ/USDT:USDT backtest was done from 2024-03-02 11:45:00 upto 2024-05-14 03:45:00 for a duration of 72 days 16:00:00 using time frame of 15m with Win Rate % - 73.83, Return % - 116.707,Expectancy % - 0.78547 and Sharpe Ratio - 0.7876.",
"stop_loss_percent_long": 0.052,
"take_profit_percent_long": 0.055,
"limit_long": 0.054,
"stop_loss_percent_short": 0.052,
"take_profit_percent_short": 0.055,
"limit_short": 0.054,
"margin_leverage": 1,
"TRAILING_ACTIVATE_PCT": 0.045,
"TRAILING_STOP_PCT": 0.005,
"roi_at_50": 0.054,
"roi_at_100": 0.05,
"roi_at_150": 0.045,
"roi_at_200": 0.04,
"roi_at_300": 0.03,
"roi_at_500": 0.01
},
"OMNI/USDT:USDT": {
"Optimizer_used": "1st backtest - Expectancy",
"model_name": "cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.91_time_20240516025817.keras",
"Optimizer_result": "For OMNI/USDT:USDT backtest was done from 2024-04-19 01:45:00 upto 2024-05-14 04:00:00 for a duration of 25 days 02:15:00 using time frame of 15m with Win Rate % - 61.36, Return % - 15.375,Expectancy % - 0.53339 and Sharpe Ratio - 0.606.",
"stop_loss_percent_long": 0.052,
"take_profit_percent_long": 0.055,
"limit_long": 0.054,
"stop_loss_percent_short": 0.052,
"take_profit_percent_short": 0.055,
"limit_short": 0.054,
"margin_leverage": 1,
"TRAILING_ACTIVATE_PCT": 0.045,
"TRAILING_STOP_PCT": 0.005,
"roi_at_50": 0.054,
"roi_at_100": 0.05,
"roi_at_150": 0.045,
"roi_at_200": 0.04,
"roi_at_300": 0.03,
"roi_at_500": 0.01
},
"ATOM/USDT:USDT": {
"Optimizer_used": "1st backtest - Expectancy",
"model_name": "cnn_model_2d_15m_ETH_May_16_SL55_TP55_ShRa_0.91_time_20240516025817.keras",
"Optimizer_result": "For ATOM/USDT:USDT backtest was done from 2024-03-02 11:45:00 upto 2024-05-14 03:45:00 for a duration of 72 days 16:00:00 using time frame of 15m with Win Rate % - 67.98, Return % - 3.37,Expectancy % - 0.32805 and Sharpe Ratio - 0.1328.",
"stop_loss_percent_long": 0.052,
"take_profit_percent_long": 0.055,
"limit_long": 0.054,
"stop_loss_percent_short": 0.052,
"take_profit_percent_short": 0.055,
"limit_short": 0.054,
"margin_leverage": 1,
"TRAILING_ACTIVATE_PCT": 0.045,
"TRAILING_STOP_PCT": 0.005,
"roi_at_50": 0.054,
"roi_at_100": 0.05,
"roi_at_150": 0.045,
"roi_at_200": 0.04,
"roi_at_300": 0.03,
"roi_at_500": 0.01
},
....................................
(all 27 assets got short listed as per paramter given by us during
optimization and backtesting with downlaoded data for the neural
network model we trained our model on)
}The provided data snippet appears to be the results of backtesting a cryptocurrency trading strategy on multiple assets. Here’s a breakdown of the information:
Structure:
- It’s a dictionary with currency pairs (e.g., “ATOM/USDT:USDT”) as keys.
Content for Each Asset:
- Optimizer_used: This specifies the optimization method used for backtesting (here, “1st backtest — Expectancy”).
- model_name: This indicates the model name used for the trading strategy (“transformer_model_55sl_55tp_eth_15m_may_13th_ShRa_0.78.keras”).
- Optimizer_result: This is a detailed description of the backtesting results for the specific asset. It includes:
- Start and end date of the backtest.
- Backtesting duration.
- Timeframe used (e.g., 15m).
- Win Rate percentage.
- Return percentage.
- Expectancy percentage.
- Sharpe Ratio.
- stop_loss_percent_long/short: These define the stop-loss percentages for long and short positions.
- take_profit_percent_long/short: These define the take-profit percentages for long and short positions.
- limit_long/short: These define the maximum price deviation allowed for entry orders (likely to prevent excessive slippage).
- margin_leverage: This specifies the leverage used for margin trading (set to 1 here, indicating no leverage).
- TRAILING_ACTIVATE_PCT & TRAILING_STOP_PCT: These define parameters for trailing stop-loss, which adjusts the stop-loss dynamically.
- roi_at_50, 100, 150, etc.: These are potentially profit targets at different holding durations (e.g., roi_at_50 might be the target profit for holding 50% of the time).
Interpretation:
- This data likely comes from a backtesting tool that evaluated a specific trading strategy on various cryptocurrencies.
- The results show performance metrics like win rate, return, and Sharpe Ratio for each asset.
- Stop-loss, take-profit, and leverage parameters define the risk management aspects of the strategy.
Shortlisted Assets and Saving:
- The statement mentions “shortlisted assets” but doesn’t explicitly show how they are identified. It’s possible that assets meeting certain performance criteria (based on the backtesting results) are considered shortlisted.
- These shortlisted assets are potentially saved in a file named “saved_assets.txt” in the same format as the provided data snippet.
Disclaimer:
- Backtesting results are not a guarantee of future performance.
- Trading cryptocurrencies involves significant risks, and you should always do your own research before making any investment decisions.
Conclusion:
This article describes a cryptocurrency trading system that utilizes a neural network model (specifically a 2D CNN model) and a trading bot called VishvaAlgo. Here’s a breakdown:
Data and Model Training:
- The system downloads historical data for over 250+ cryptocurrency assets on Binance Futures from TradingView.
- It trains a 2D CNN-based neural network model, achieving a claimed return of 9,800%+ on Ethereum (ETHUSDT) in 3 years on a 15-minutes time frame data with over 100,000 rows trained model with 193+ features used for finding the best possible estimation for going neutral, long and short using the classification based 2D CNN model. (important to note: this returns vary from system to system based on trained data and needs re-verification).
Hyperparameter Optimization and Asset Selection:
- The system uses Hyperopt (a hyperparameter optimization library) to identify the most suitable assets for the trained model among the downloaded data.
- Each shortlisted asset has a unique set of parameters like stop-loss, take-profit, leverage, tailored for the model’s predictions.
VishvaAlgo — The Trading Bot:
- VishvaAlgo helps automate live trading using the trained model and the shortlisted assets with their pre-defined parameters.
- The bot offers easy integration with various neural network models for classification.
- A video explaining VishvaAlgo’s features and benefits is available — Link
Benefits of VishvaAlgo:
- Automates trading based on the trained model and optimized asset selection.
- Offers easy integration with user-defined neural network models.
- Provided detailed explanation and installation guide for purchase through my Patreon page.
Youtube Link Explanation of VishvaAlgo v4.x Features — Link
get entire code and profitable algos @ https://patreon.com/pppicasso
Disclaimer: Trading involves risk. Past performance is not indicative of future results. VishvaAlgo is a tool to assist traders and does not guarantee profits. Please trade responsibly and conduct thorough research before making investment decisions.
Warm Regards,
Puranam Pradeep Picasso
Linkedin — https://www.linkedin.com/in/puranampradeeppicasso/
Patreon — https://patreon.com/pppicasso
Facebook — https://www.facebook.com/puranam.p.picasso/
Twitter — https://twitter.com/picasso_999
